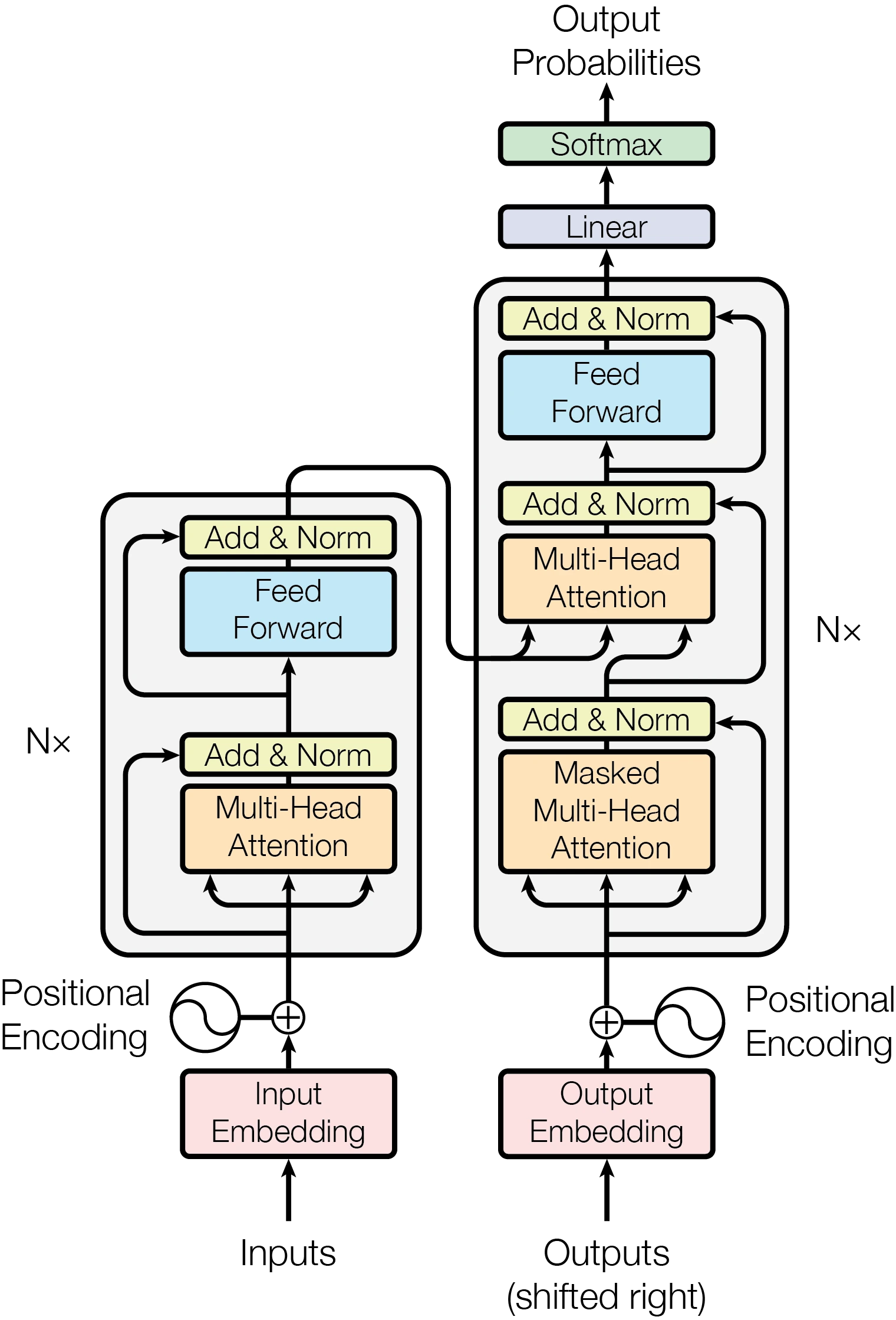
The Transformer - model
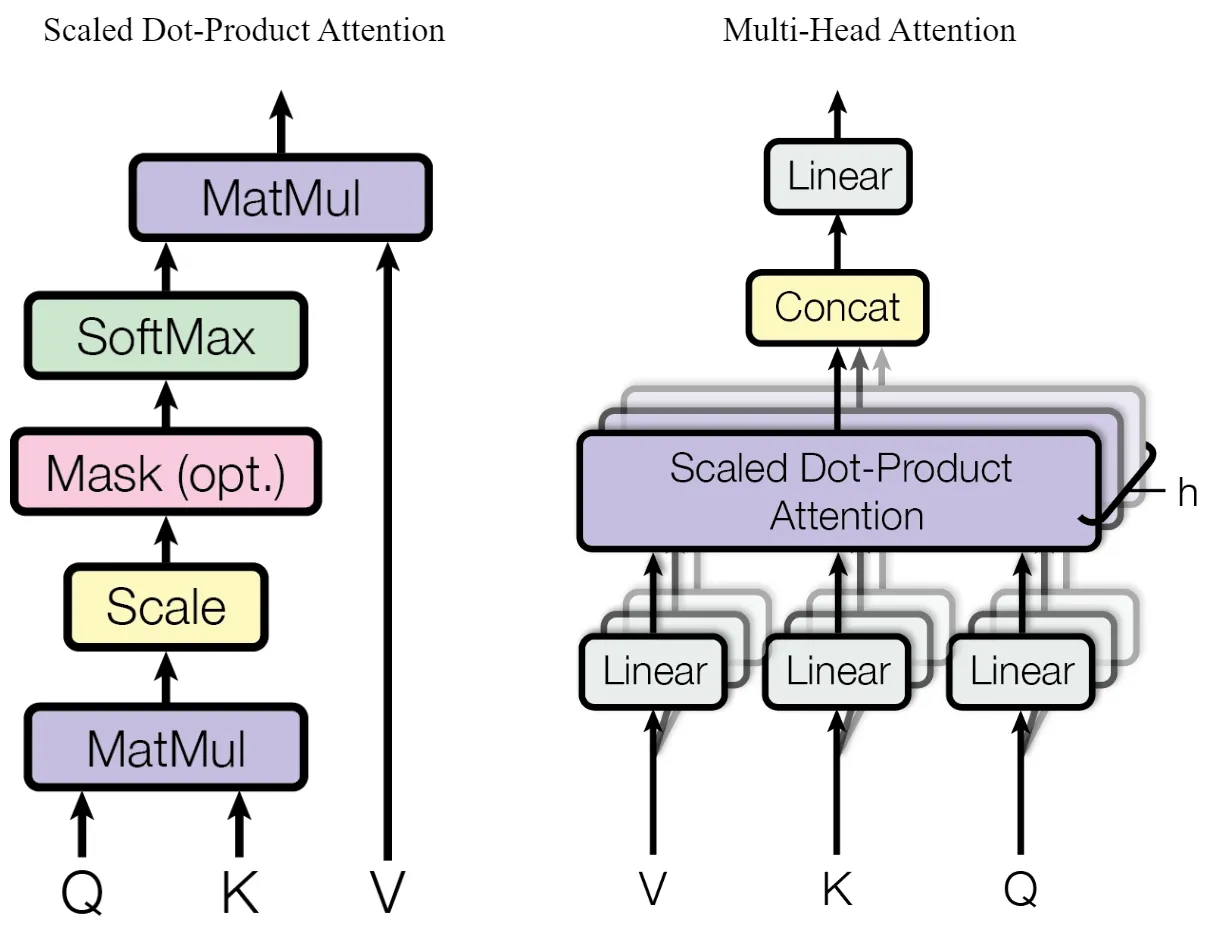
architecture.(left) Scaled Dot-Product Attention.
(right) Multi-Head Attention consists of several attention layers
running in parallel.
2021
ICLR
1.
An Image is Worth 16x16 Words: Transformers for Image Recognition at
Scale
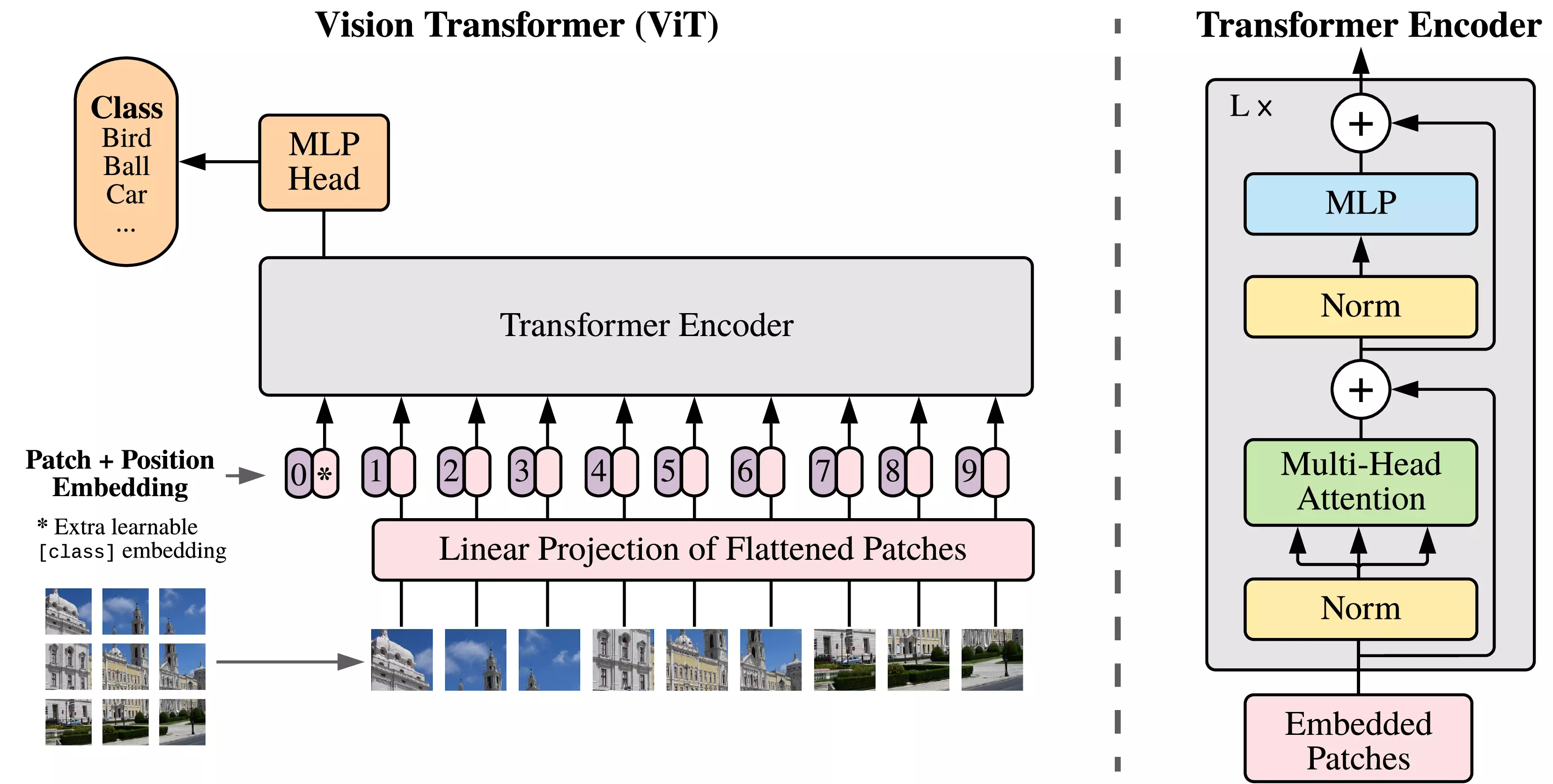
Model overview. We split an image into
fixed-size patches, linearly embed each of them, add position
embeddings, and feed the resulting sequence of vectors to a standard
Transformer encoder. In order to perform classification, we use the
standard approach of adding an extra learnable "classification token" to
the sequence. The illustration of the Transformer encoder was inspired
by Vaswani et al. (2017).
ICCV
1.
Emerging Properties in Self-Supervised Vision Transformers
Self-attention from a Vision Transformer
with \(8 \times 8\) patches trained
with no supervision. We look at the self-attention of the [CLS] token on
the heads of the last layer. This token is not attached to any label nor
supervision. These maps show that the model automatically learns
class-specific features leading to unsupervised object
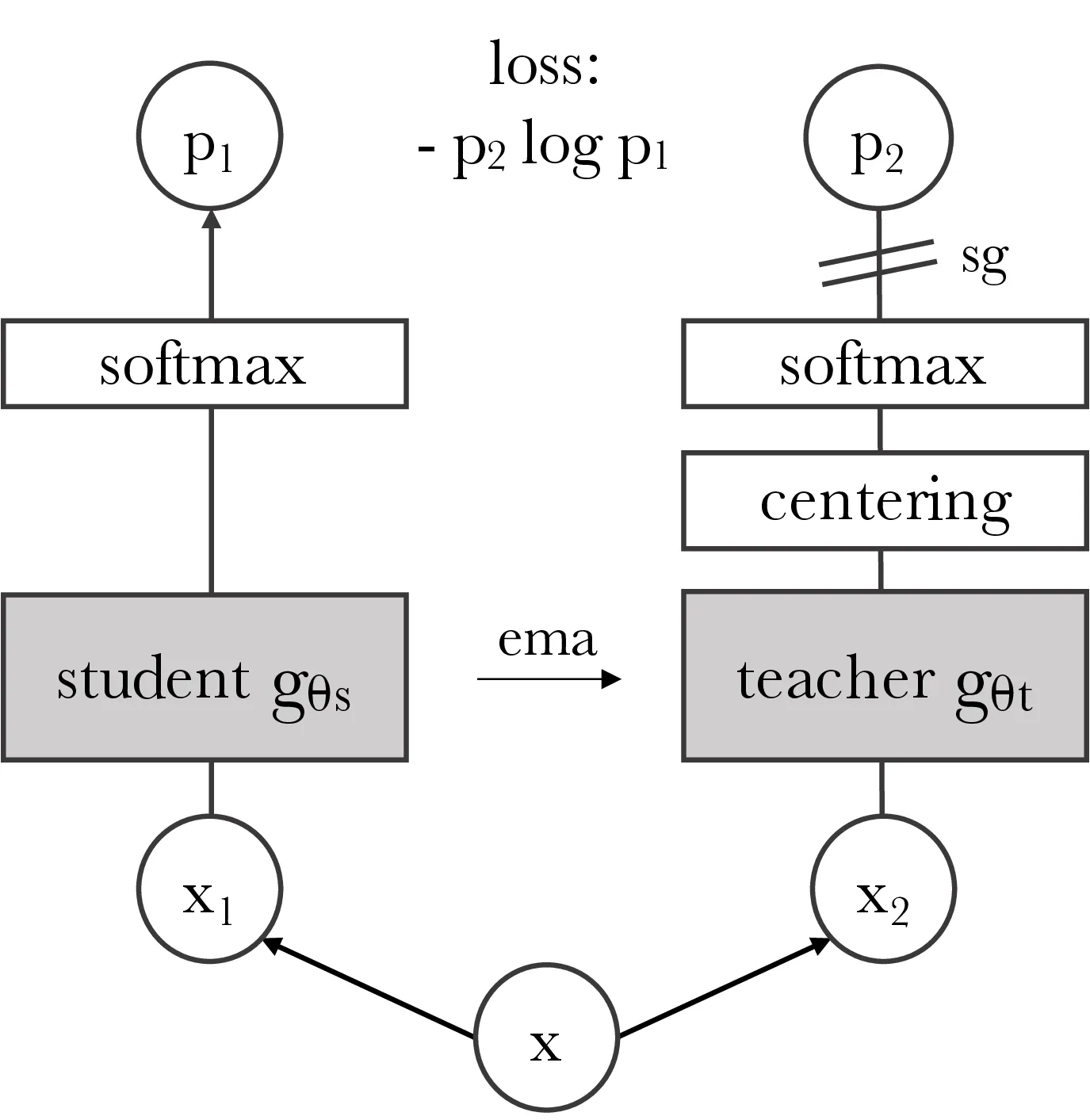
segmentations.Self-distillation with no labels. We
illustrate DINO in the case of one single pair of views \((x_1, x_2)\) for simplicity. The model
passes two different random transformations of an input image to the
student and teacher networks. Both networks have the same architecture
but different parameters. The output of the teacher network is centered
with a mean computed over the batch. Each networks outputs a \(K\) dimensional feature that is normalized
with a temperature softmax over the feature dimension. Their similarity
is then measured with a cross-entropy loss. We apply a stop-gradient
(sg) operator on the teacher to propagate gradients only through the
student. The teacher parameters are updated with an exponential moving
average (ema) of the student parameters.
2022
CVPR
1.
ES6D: A Computation Efficient and Symmetry-Aware 6D Pose Regression
Framework
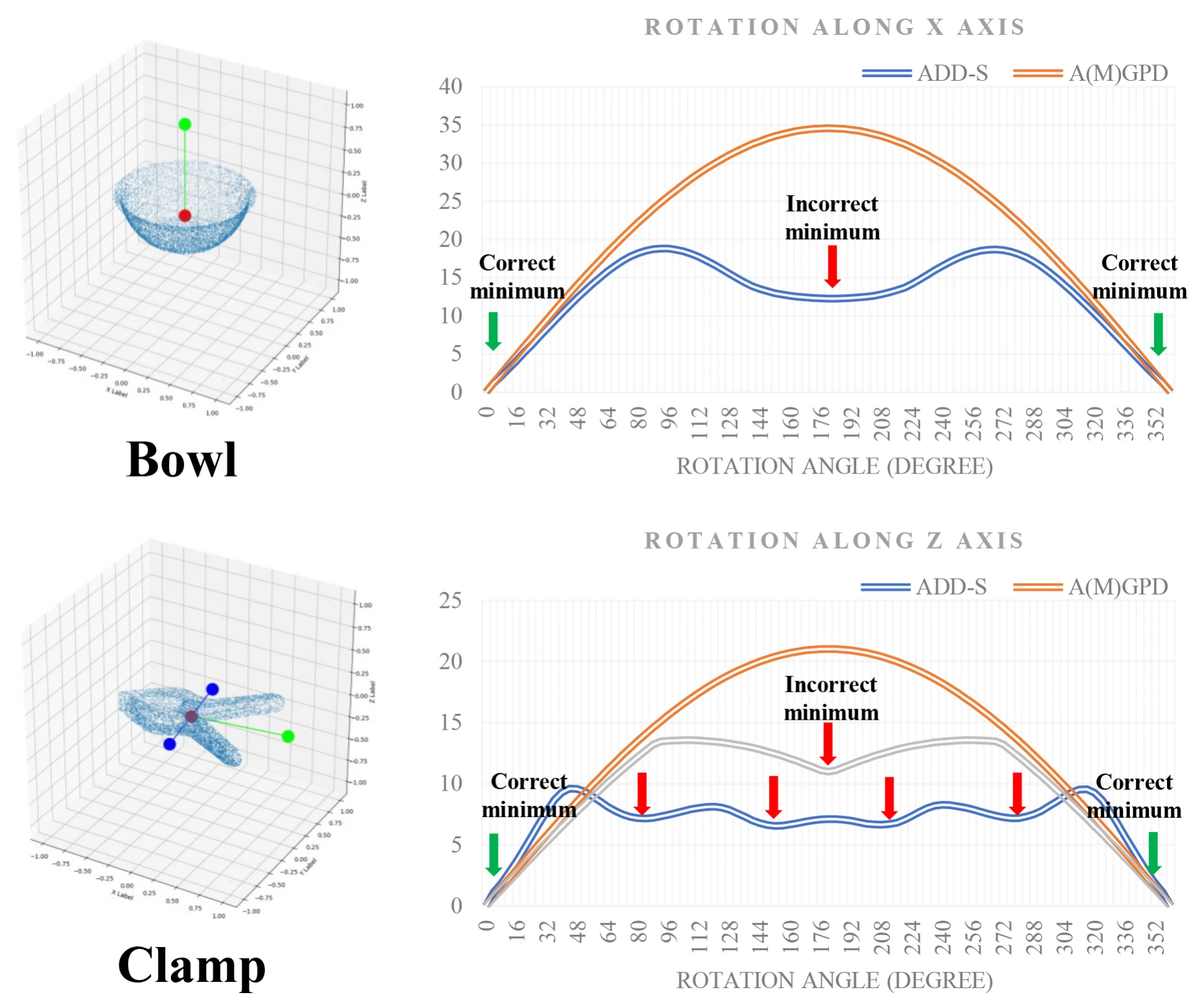
Comparison of A(M)GPD and ADD-S. Axis X
shows the rotation angle of the object (from 0° to 360°). Axis Y shows
the calculated distance. We set the initial pose as the ground truth. As
we can see, all minima are mapped to correct poses in the A(M)GPD curve
and several minima point to incorrect poses in the ADD-S
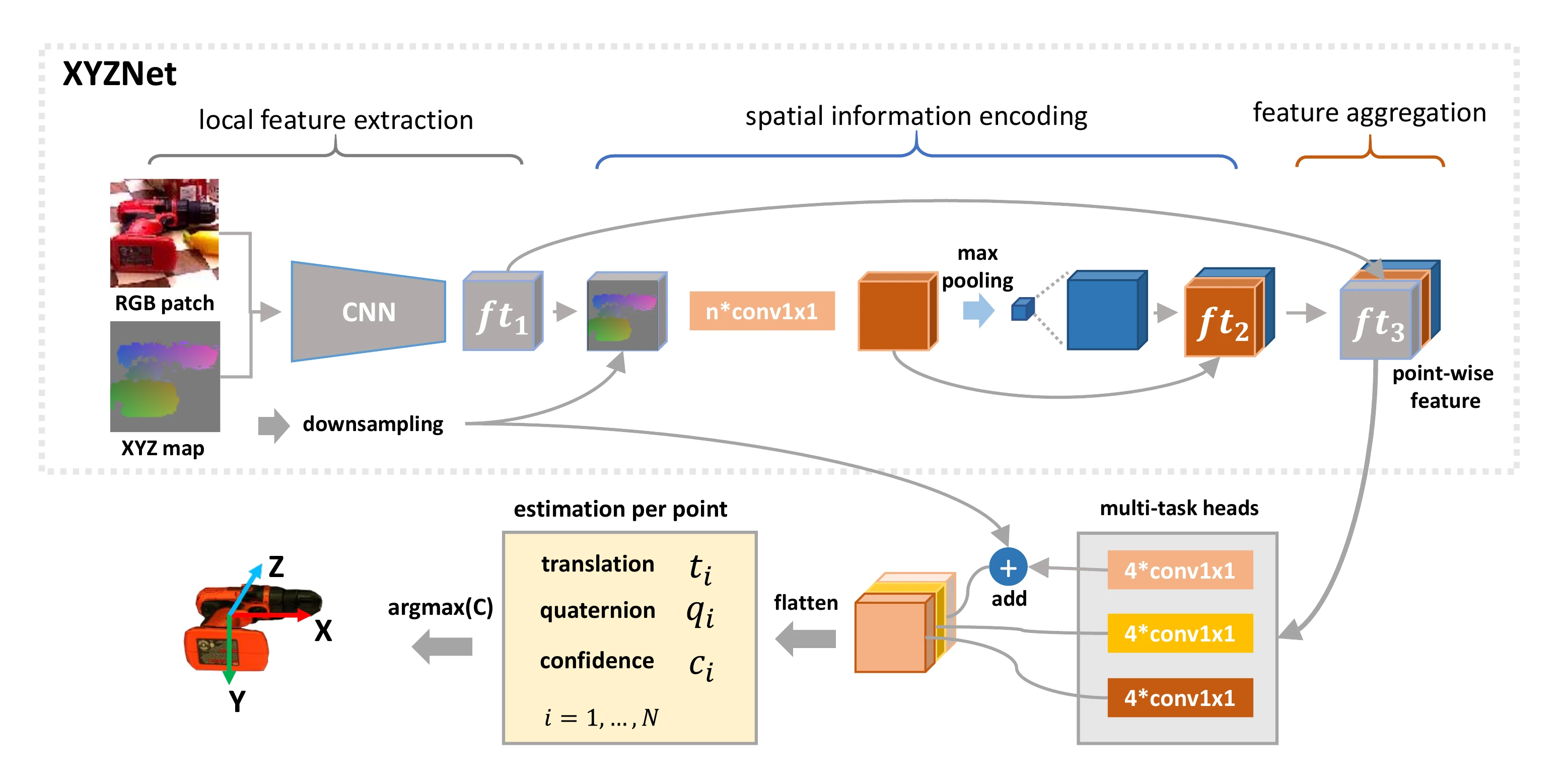
curve.Network overview. First, the RGB-XYZ data
is generated from the RGB-D image. The RGB-XYZ data is fed into a CNN
module to extract local features, which encode color and geometry
information. Second, the point cloud features are obtained by a
PointNet-like CNN module and padded to the same size as the local
features. Then, the local features and point cloud features are
concatenated as the point-wise features for poses estimation. Finally,
the pose with the maximum confidence is chosen as the final
result.
2023
ICCV
1.
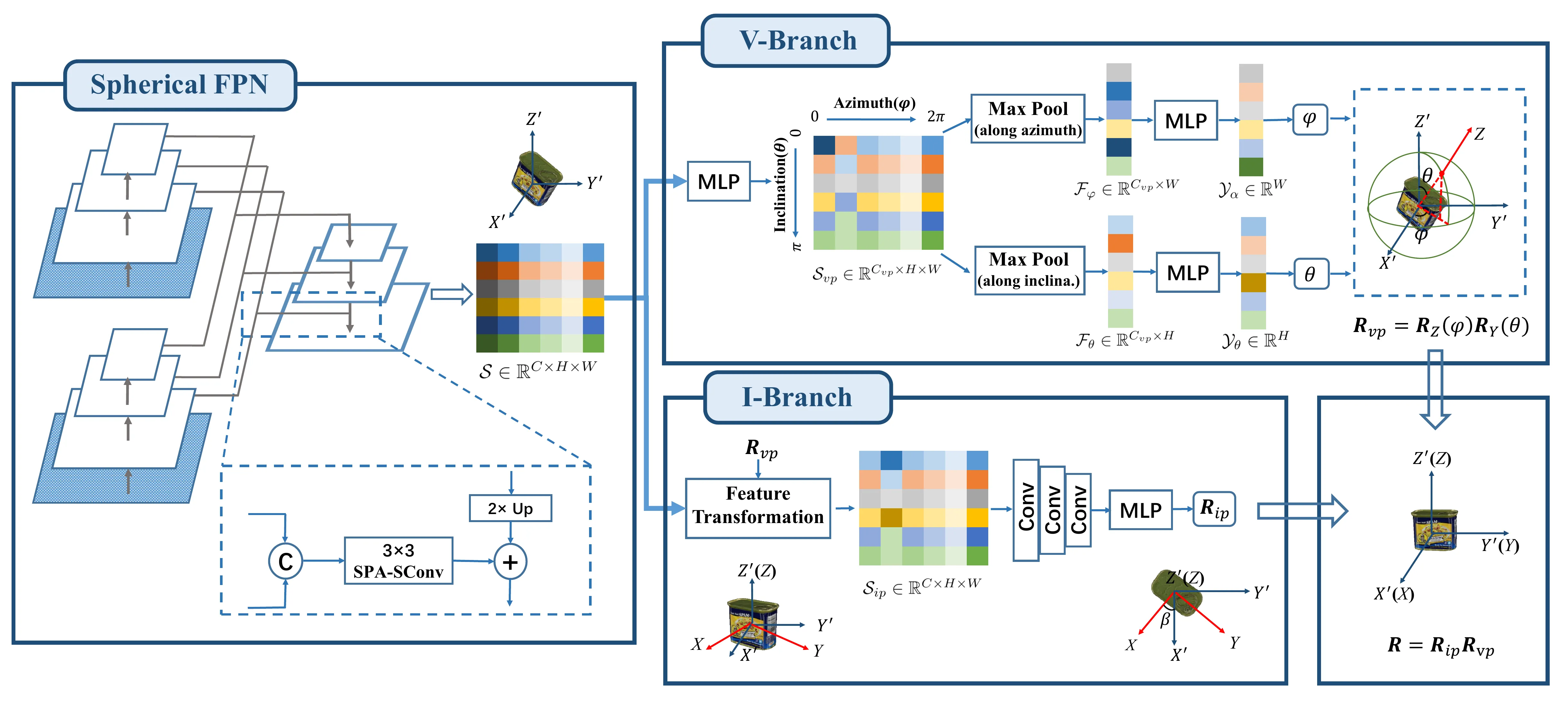
VI-Net: Boosting Category-level 6D Object Pose Estimation via Learning
Decoupled Rotations on the Spherical Representations
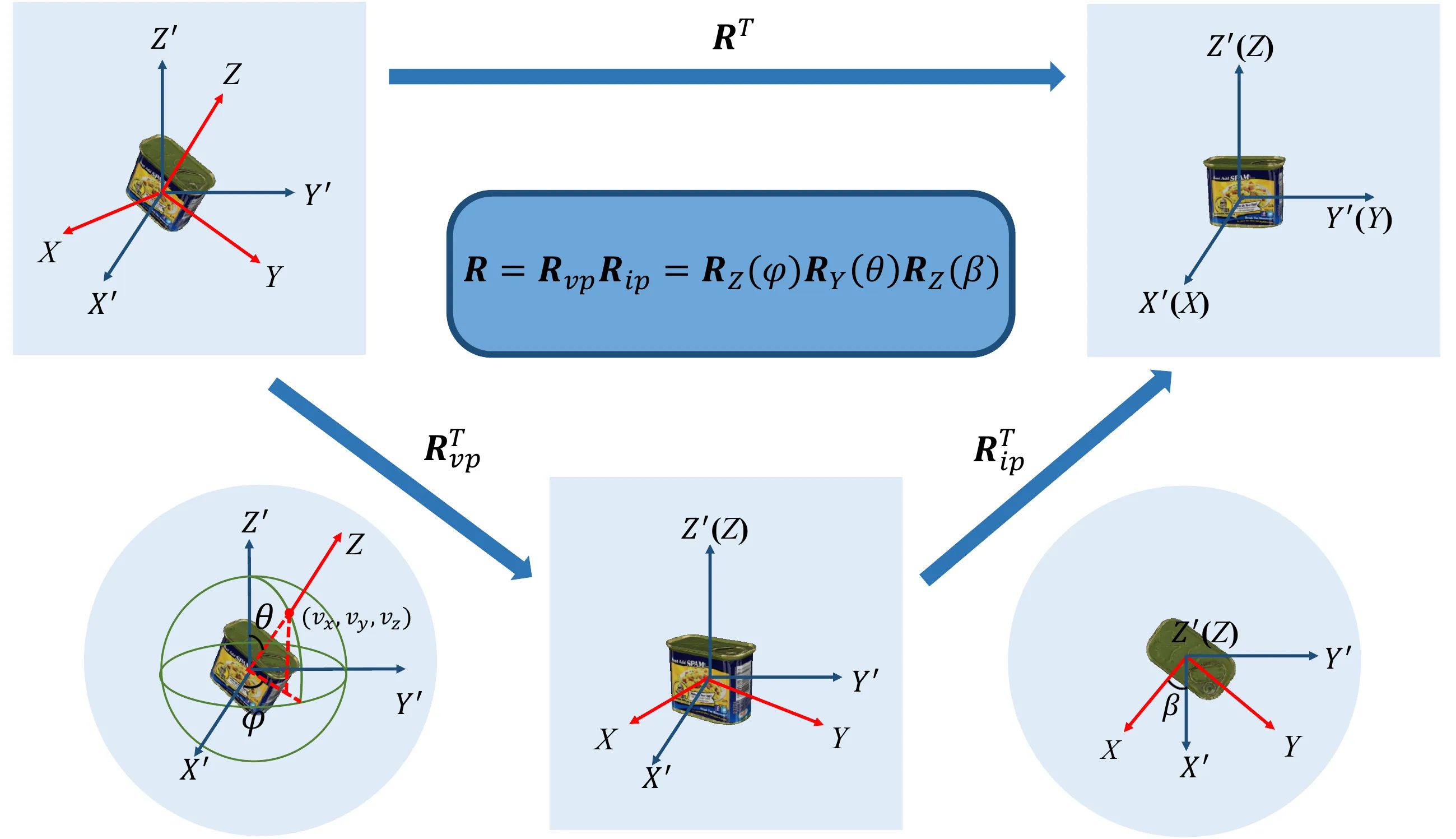
An illustration of the factorization of
rotation \(\mathbf{R}\) into a
viewpoint (out-of-plane) rotation \(\mathbf{R}_{vp}\) and an in-plane rotation
\(\mathbf{R}_{ip}\) (around Z-axis).
Notations are explained in Sec. 3.An illustration of VI-Net for rotation
estimation. We firstly construct a Spherical Feature Pyramid Network
based on spatial spherical convolutions (SPA-SConv) to exact the
high-level spherical feature map \(\mathcal{S}\). On top of \(\mathcal{S}\), a V-Branch is employed to
search the canonical zenith direction on the sphere via binary
classification for the generation of the viewpoint rotation \(\mathbf{R}_{vp}\), while another I-Branch
is used to estimate the in-plane rotation \(\mathbf{R}_{ip}\) by transforming \(\mathcal{S}\) to view the object from the
canonical zenith direction. Finally we have \(\mathbf{R} =
\mathbf{R}_{vp}\mathbf{R}_{ip}\). Best view in the electronic
version.
2024
CVPR
1.
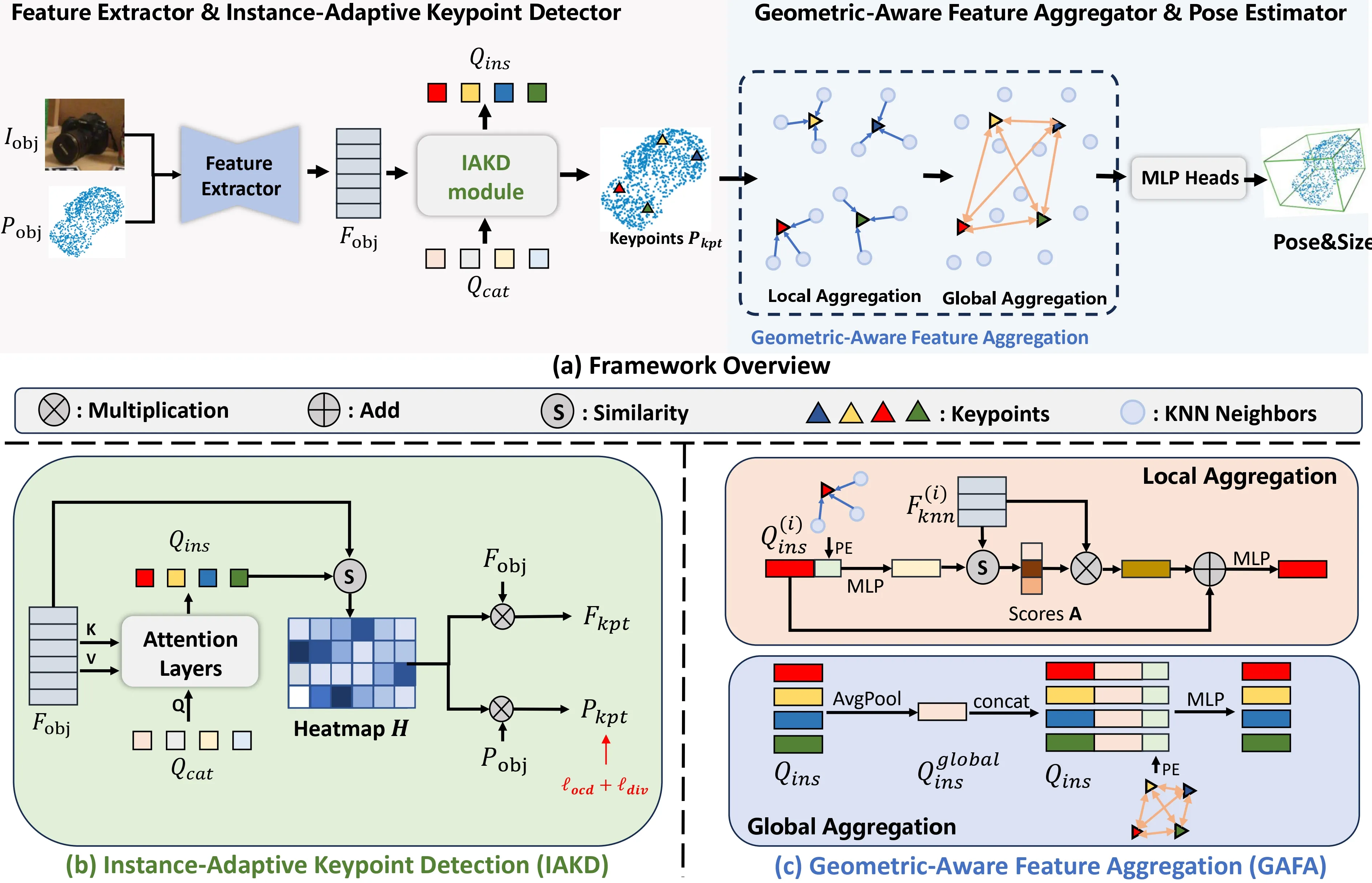
Instance-Adaptive and Geometric-Aware Keypoint Learning for
Category-Level 6D Object Pose Estimation
a) The visualization for the
correspondence error map and final pose estimation of the dense
correspondence-based method, DPDN [17]. Green/red indicates small/large
errors and GT/predicted bounding box. b) Points belonging to different
parts of the same instance may exhibit similar visual features. Thus,
the local geometric information is essential to distinguish them from
each other. c) Points belonging to different instances may exhibit
similar local geometric structures. Therefore, the global geometric
information is crucial for correctly mapping them to the corresponding
NOCS coordinates.a) Overview of the proposed AG-Pose. b)
Illustration of the IAKD module. We initialize a set of category-shared
learnable queries and convert them into instance-adaptive detectors by
integrating the object features. The instance-adaptive detectors are
then used to detect keypoints for the object. To guide the learning of
the IAKD module, we futher design the \(L_{div}\) and \(L_{ocd}\) to constrain the distribution of
keypoints. c) Illustration of the GAFA module. Our GAFA can efficiently
integrate the geometric information into keypoint features through a
two-stage feature aggregation process.
2.
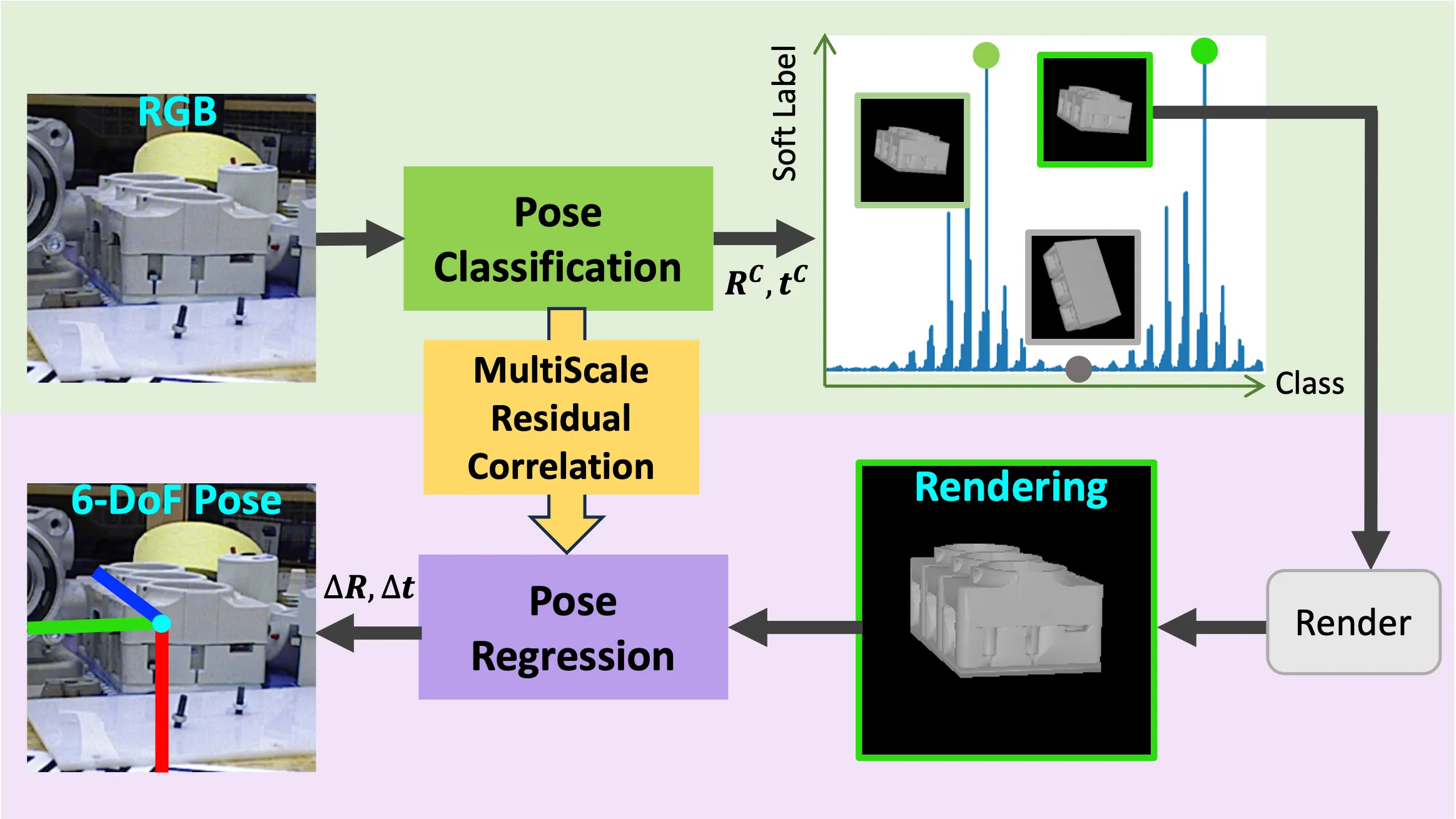
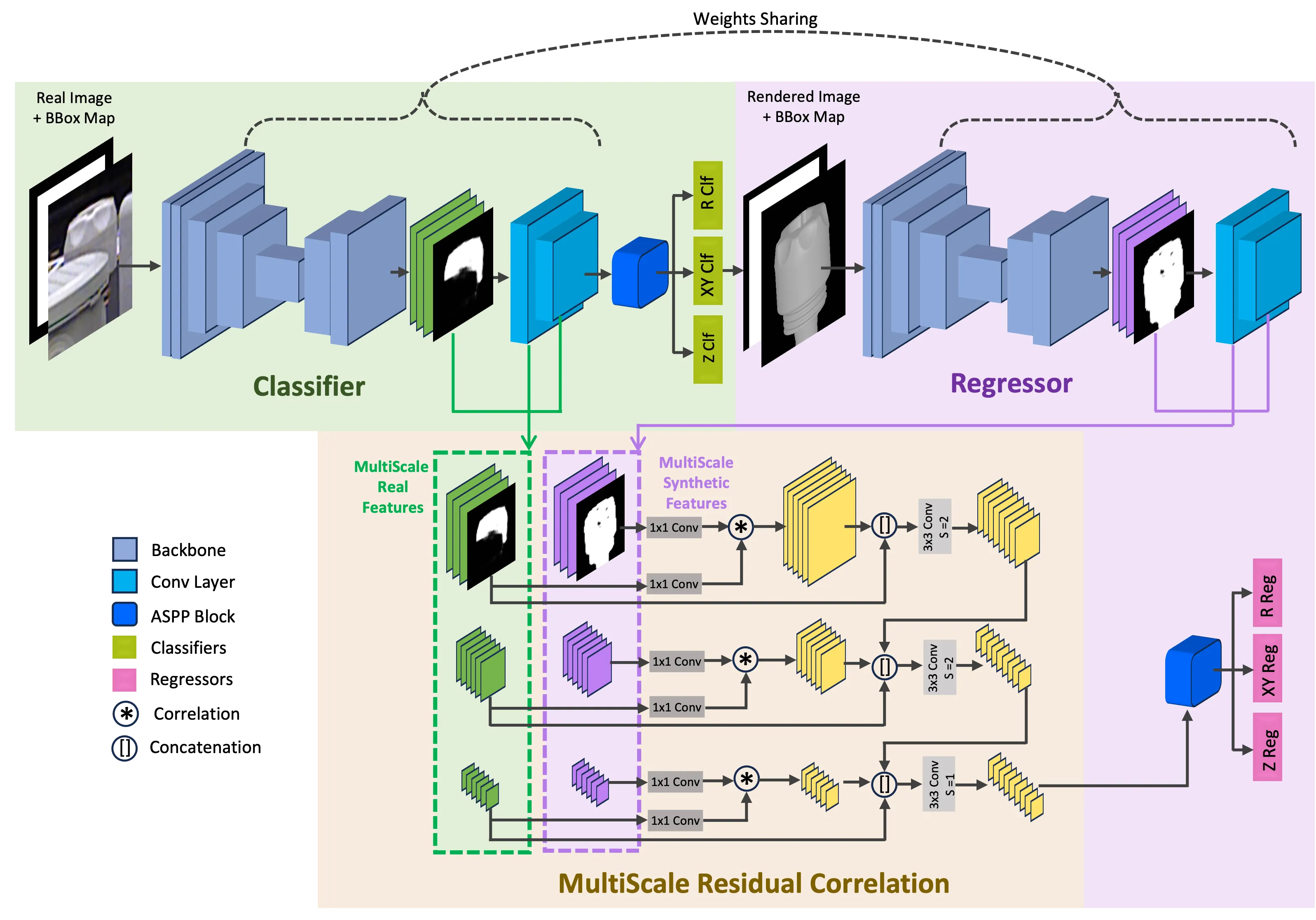
MRC-Net: 6-DoF Pose Estimation with MultiScale Residual Correlation
MRC-Net features a single-shot sequential
Siamese structure of two stages, where the second stage conditions on
the first classification stage outcome through multi-scale residual
correlation of poses between input and rendered images.MRC-Net Architecture. The classifier and
regressor stages employ a Siamese structure with shared weights. Both
stages take the object crop and its bounding box map as input, and
extract image features to detect the visible object mask, which are
concatenated together to estimate object pose. The classifier first
predicts pose labels. These predictions, along with the 3D CAD model,
are then used to render an image estimate, which serves as input for the
second stage. Features from the rendered image are correlated with those
from real images in the MRC layer. These correlation features undergo
ASPP processing within the rendered branch to regress the pose
residuals.
3.
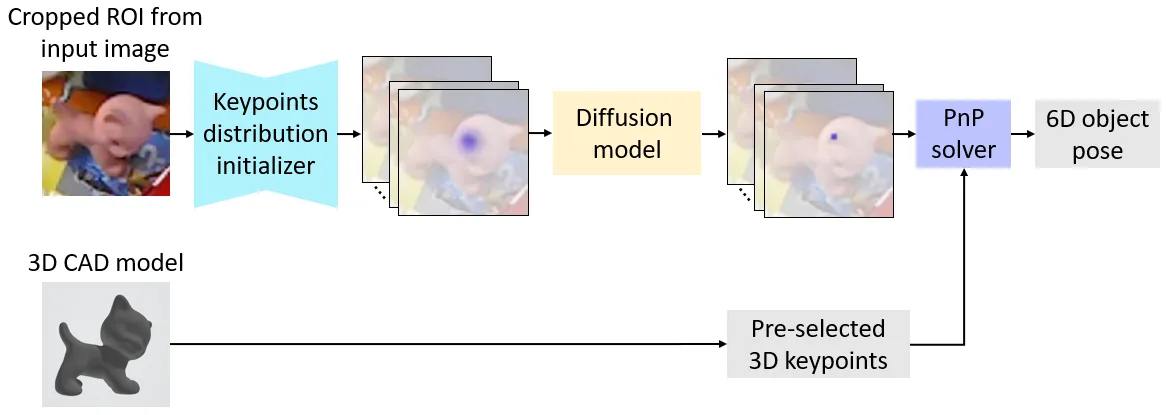
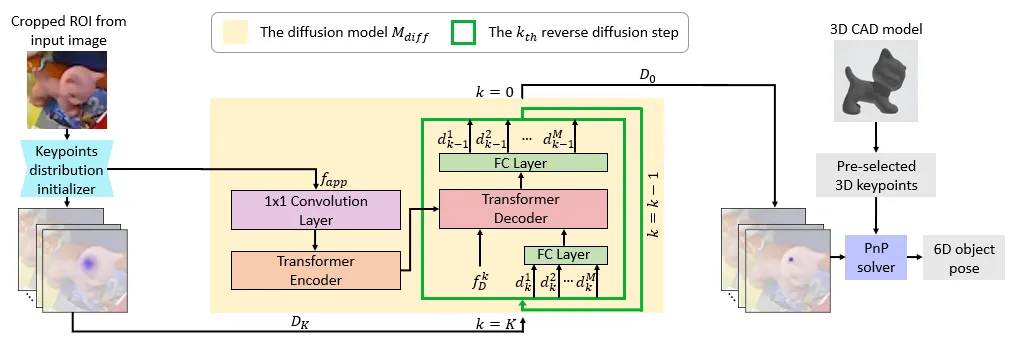
6D-Diff: A Keypoint Diffusion Framework for 6D Object Pose
Estimation
Overview of our proposed 6D-Diff
framework. As shown, given the 3D keypoints from the object 3D CAD
model, we aim to detect the corresponding 2D keypoints in the image to
obtain the 6D object pose. Note that when detecting keypoints, there are
often challenges such as occlusions (including self-occlusions) and
cluttered backgrounds that can introduce noise and indeterminacy into
the process, impacting the accuracy of pose prediction.Illustration of our framework. During
testing, given an input image, we first crop the Region of Interest
(ROI) from the image through an object detector. After that, we feed the
cropped ROI to the keypoints distribution initializer to obtain the
heatmaps that can provide useful distribution priors about keypoints, to
initialize \(D_K\). Meanwhile, we can
obtain object appearance features \(f_\text{app}\). Next, we pass \(f_\text{app}\) into the encoder, and the
output of the encoder will serve as conditional information to aid the
reverse process in the decoder. We sample \(M\) sets of 2D keypoints coordinates from
\(D_K\), and feed these \(M\) sets of coordinates into the decoder to
perform the reverse process iteratively together with the step embedding
\(f_k\). At the final reverse step
(K-th step), we average \(\{d_0\}_{i =
1}^M\) as the final keypoints coordinates prediction \(\mathbf{d}_0\), and use \(d_0\) to compute the 6D pose with the
pre-selected 3D keypoints via a PnP solver.
4.
SecondPose: SE(3)-Consistent Dual-Stream Feature Fusion for
Category-Level Pose Estimation
Categorical SE(3)-consistent features. We
visualize our fused features by PCA. Colored points highlight the most
corresponding parts, where our proposed feature achieves consistent
alignment cross instances (left vs. middle) and maintains consistency on
the same instance of different poses (middle vs. right).Illustration of SecondPose. Semantic
features are extracted using the DINOv2 model (A), and the HP-PPF
feature is computed on the point cloud (B). These features, combined
with RGB values, are fused into our SECOND feature \(F_f\) (C) using stream-specific modules
\(L_s\), \(L_g\), \(L_c\), and a shared module \(L_f\) for concatenated features. The
resulting fused features, in conjunction with the point cloud, are
utilized for pose estimation (D).
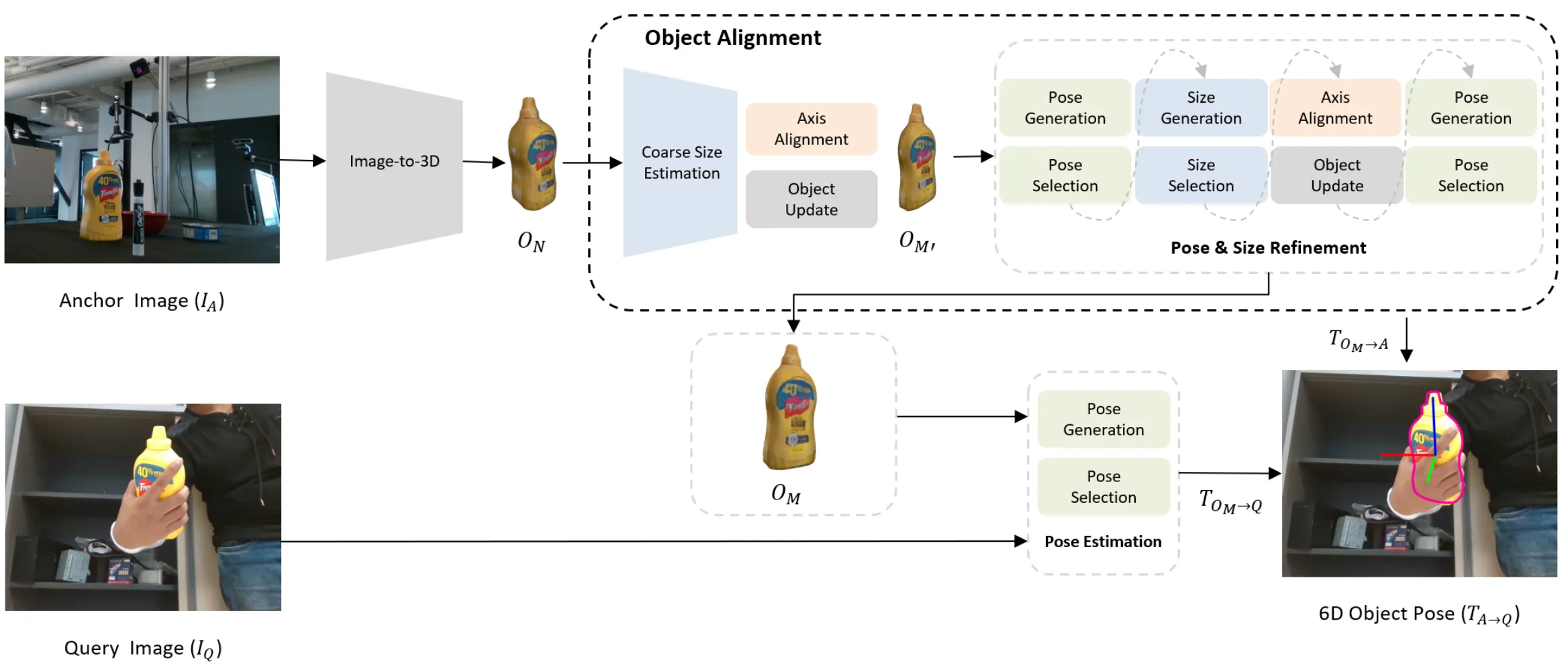
Our method accurately estimates 6D object
pose for novel objects on drastically different scenes and viewpoints
using only a single RGB-D anchor image. We achieve robust pose
estimation without requiring precise CAD models or posed multi-view
reference images.Overview of the Any6D framework for
model-free object pose estimation. First, we reconstruct normalized
object shape \(O_N\) from the
image-to3D model. Then, we estimate accurate object pose and size from
anchor image \(I_A\) using the proposed
object alignment (Sec. 3.1). Next, we use the query image \(I_Q\) to estimate the pose with the
reconstructed metric-scale object shape \(O_M\) (Sec. 3.2).
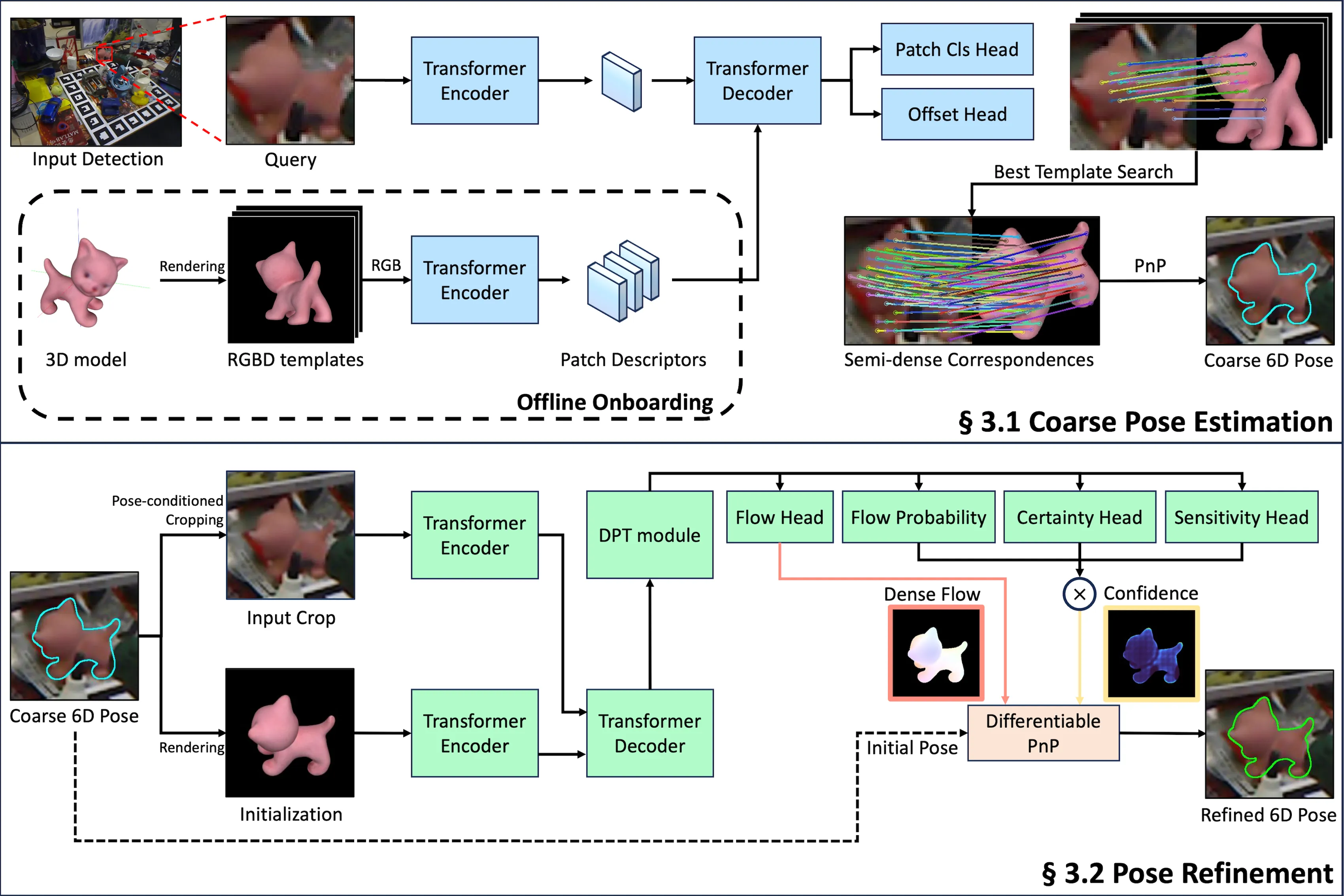
Examples of 6D pose estimation of novel
objects. Our method estimates semi-dense or dense correspondences
between the input image and rendered images and uses them to estimate
the pose.Overview. We estimate object pose through
two main stages. In the Coarse Pose Estimation stage (Sec 3.1), we
estimate semidense correspondences between the query image and templates
and compute the initial pose using PnP. In the Pose Refinement stage
(Sec 3.2), we refine the initial pose by estimating dense flow between
the query and rendered images. Both stages utilize transformer encoders
and decoders with identical structures, with the Pose Refinement stage
additionally incorporating a DPT module after the decoder for dense
prediction.
3.
One2Any: One-Reference 6D Pose Estimation for Any Object
Given a single RGB-D image as a reference
for an unseen object, our method estimates the pose of the object in a
given query image, relative to the reference. The method first predicts
a Reference Object Pose Embedding (ROPE) that encodes the object's
texture, shape, and pose priors. During inference, each query RGB image
is processed through a decoder to predict the Reference Object
Coordinate (ROC) map and estimate the relative pose to the reference
image. This approach effectively handles large viewpoint
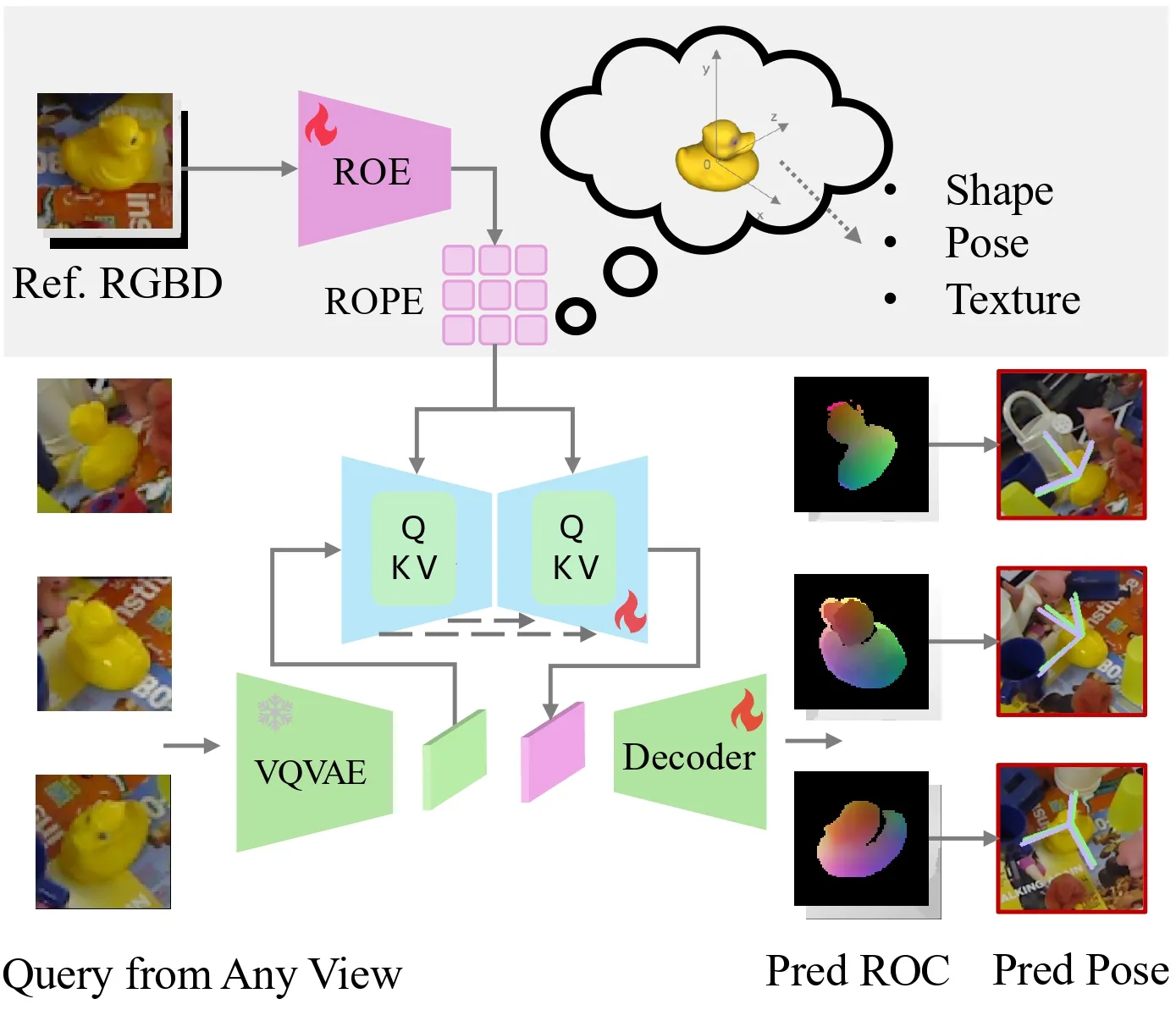
changes.Network architecture. The network takes a
reference RGB-D image as input and learns a Reference Object Pose
Embedding (ROPE) through a Reference Object Encoder (ROE). This
embedding is subsequently integrated with the query feature map, which
is extracted using a pre-trained VQVAE model [48] with the query RGB
image as input. We use the U-Net architecture for effective integrate
the ROPE with the query feature with cross-attentions layers. The
decoder is trained to predict the ROC map. The final pose estimation is
computed using the Umeyama algorithm [53].
4.
UNOPose: Unseen Object Pose Estimation with an Unposed RGB-D Reference
Image
Illustration of unseen object pose
estimation. Given a query image presenting a target object unseen during
training, we aim to estimate its segmentation and 6DoF pose w.r.t. a
reference frame. While previous methods [43, 57, 77, 90] often rely on
the CAD model or multiple RGB(-D) images for reference, we merely use
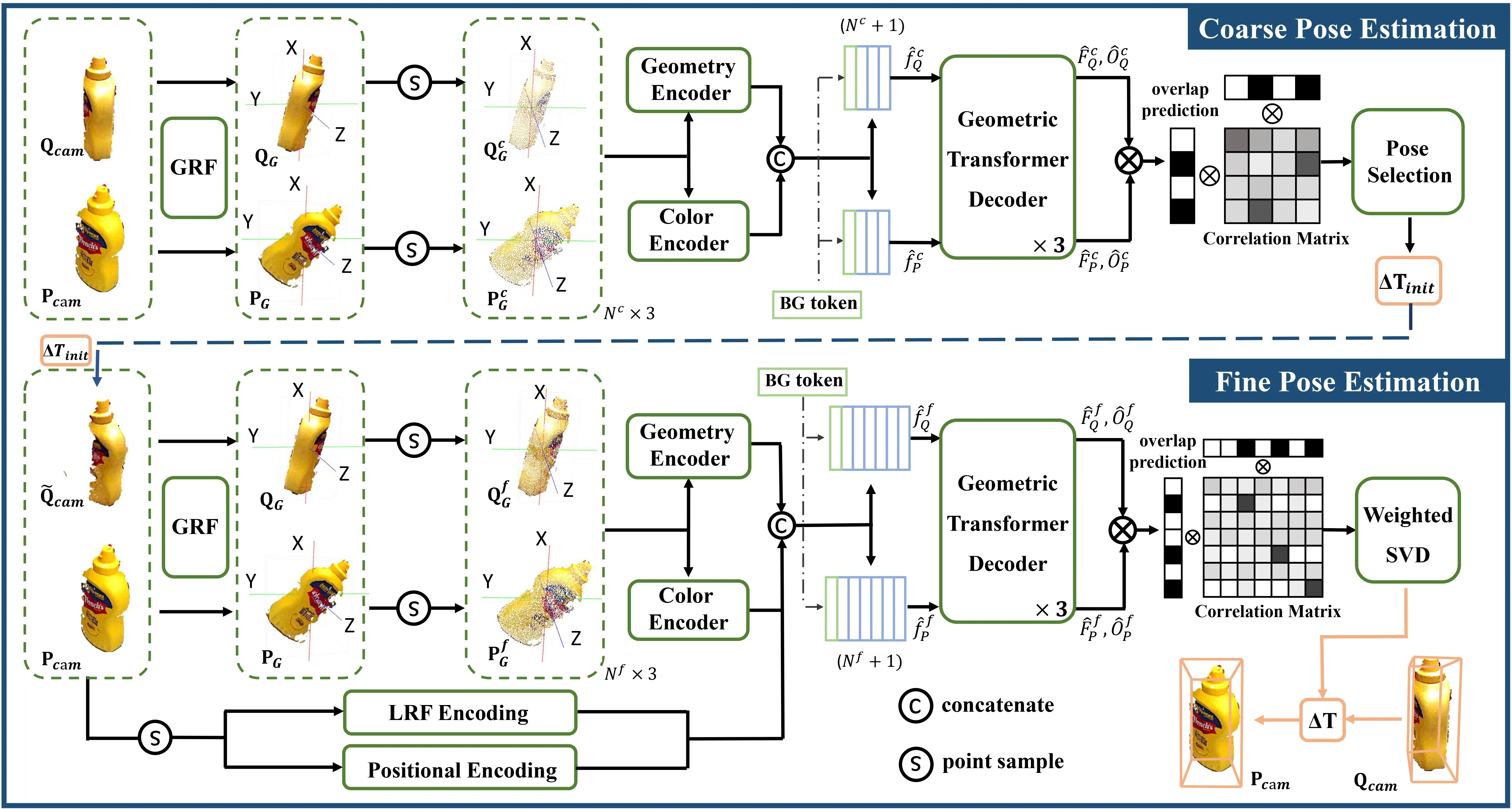
one unposed RGB-D reference image.The network architecture of UNOPose.
Given the query and reference point clouds \(\mathbf{Q}_{cam}\) and \(\mathbf{P}_{cam}\) in the camera frame,
UNOPose first transforms them into the \(SE(3)\)-invariant global reference frame
(GRF). Then feature descriptors are extracted from sparse point sets for
constructing the coarse correlation matrix. For achieving precise
correspondences, the fine pose estimation module exploits structural
details using positional encoding and local reference frame (LRF)
encoding.
![Self-attention from a Vision Transformer with 8 \times 8 patches trained with no supervision. We look at the self-attention of the [CLS] token on the heads of the last layer. This token is not attached to any label nor supervision. These maps show that the model automatically learns class-specific features leading to unsupervised object segmentations.](https://img.032802.xyz/paper-reading/2021/emerging-properties-in-self-supervised-vision-transformers_2021_Caron/attn6.webp)
![a) The visualization for the correspondence error map and final pose estimation of the dense correspondence-based method, DPDN [17]. Green/red indicates small/large errors and GT/predicted bounding box. b) Points belonging to different parts of the same instance may exhibit similar visual features. Thus, the local geometric information is essential to distinguish them from each other. c) Points belonging to different instances may exhibit similar local geometric structures. Therefore, the global geometric information is crucial for correctly mapping them to the corresponding NOCS coordinates.](https://img.032802.xyz/paper-reading/2024/instance-adaptive-and-geometric-aware-keypoint-learning-for-category-level-6d-object-pose-estimation_2024_Lin/motivation_v7.webp)
-consistent-dual-stream-feature-fusion-for-category-level-pose-estimation_2024_Chen/second_teaser.webp)
-consistent-dual-stream-feature-fusion-for-category-level-pose-estimation_2024_Chen/pipe.webp)


![Network architecture. The network takes a reference RGB-D image as input and learns a Reference Object Pose Embedding (ROPE) through a Reference Object Encoder (ROE). This embedding is subsequently integrated with the query feature map, which is extracted using a pre-trained VQVAE model [48] with the query RGB image as input. We use the U-Net architecture for effective integrate the ROPE with the query feature with cross-attentions layers. The decoder is trained to predict the ROC map. The final pose estimation is computed using the Umeyama algorithm [53].](https://img.032802.xyz/paper-reading/2025/one2any-one-reference-6d-pose-estimation-for-any-object_2025_Liu/architecture.webp)
![Illustration of unseen object pose estimation. Given a query image presenting a target object unseen during training, we aim to estimate its segmentation and 6DoF pose w.r.t. a reference frame. While previous methods [43, 57, 77, 90] often rely on the CAD model or multiple RGB(-D) images for reference, we merely use one unposed RGB-D reference image.](https://img.032802.xyz/paper-reading/2024/unopose-unseen-object-pose-estimation-with-an-unposed-rgb-d-reference-image_2025_Liu/teaser.webp)