【论文笔记】Any6D: Model-free 6D Pose Estimation of Novel Objects
Any6D: Model-free 6D Pose Estimation of Novel Objects
| 方法 | 类型 | 训练输入 | 推理输入 | 输出 | pipeline |
|---|---|---|---|---|---|
| Any6D | 任意级 | RGBDs | RGBDs | 相对\(\mathbf{R}, \mathbf{t}\) |
- 2025.04.05:任意物体方法,输入一张锚点图\(I_A\)和一张查询图\(I_Q\),估计锚点图到查询图的相对位姿。首先基于锚点图,用图生3D模型来生成3D模型\(O_N\),然后将\(O_N\)与\(I_A\)对齐,对齐的过程会得到变换\(\mathbf{T}_a \in \text{SE}(3)\)和物体大小\(s \in \mathbb{R}^3\),使用这两个变换能将\(O_N\)变换为\(O_{M^\prime}\)。\(O_{M^\prime}\)会再次进行优化得到\(O_M\)和\(\mathbf{T}_{O_M \to A}\),然后基于\(O_M\)和\(I_Q\),使用渲染-比较的方法,得到\(\mathbf{T}_{O_M \to Q}\)。结合\(\mathbf{T}_{O_M \to A}\)和\(\mathbf{T}_{O_M \to Q}\),得到\(\mathbf{T}_{A \to Q}\)。
Abstract
1. Introduction

The main contributions of our work are as follows:
- We introduce Any6DPose, a novel framework that enables 6D pose and size estimation of novel objects in different scenes from only a single reference image.
- We propose a straightforward yet effective object alignment technique that addresses the challenges of existing 3D generation models, specifically improving 2D-3D alignment and size estimation for accurate pose estimation.
- We validate our approach through extensive experiments, demonstrating superior performance compared to state-of-the-art methods across five benchmark datasets.
2. Related Works
3. Method
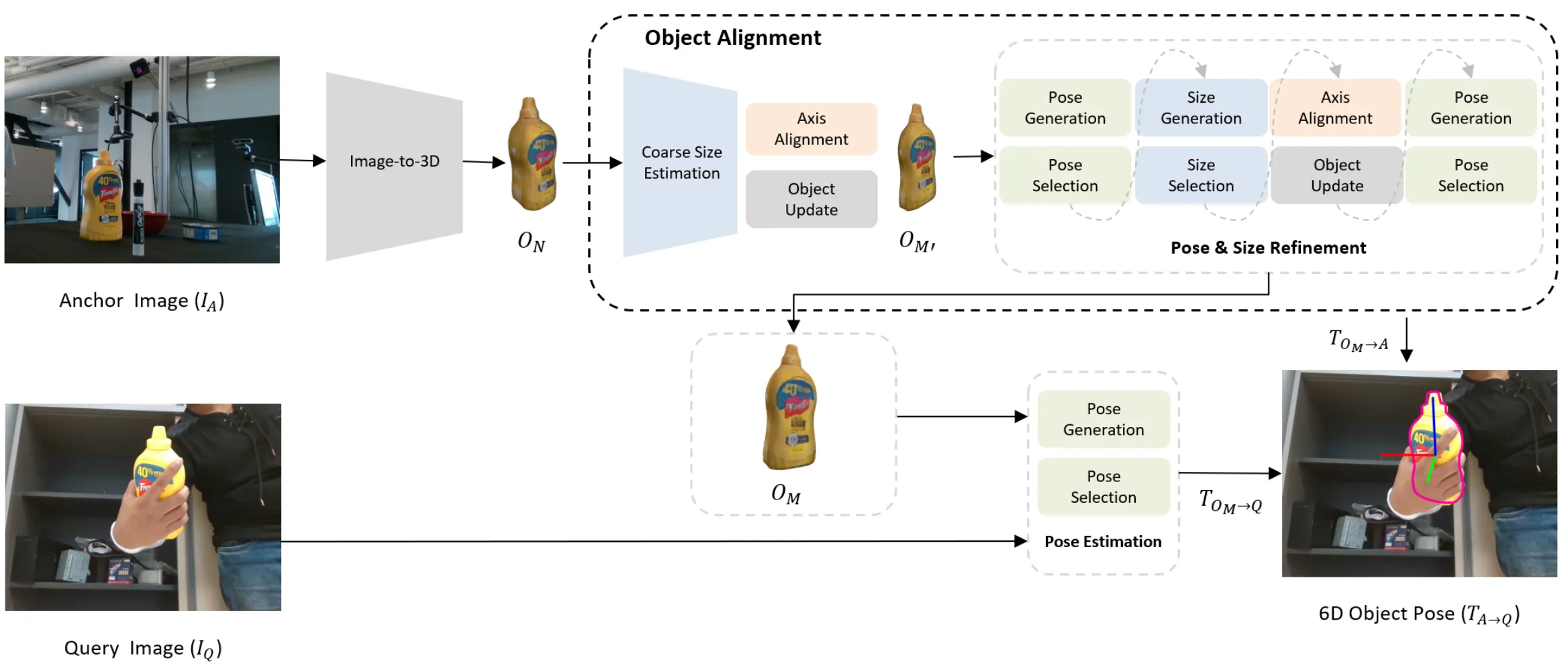
给定锚点RGBD图像\(I_A\)和查询RGBD图像\(I_Q\),我们的任务是估计出这两张图像之间的相对位姿。查询图像可能在和锚点图像完全不同的视角和场景下捕获同一对象。我们的任务是估计出\(I_A\)和\(I_Q\)之间的相对位姿\(\mathbf{T}_{A \to Q} \in \text{SE}(3)\),其中\(\mathbf{T}_{A \to Q}\)定义为一个刚体变换\([R | t]\),包含一个旋转\(R \in \text{SO}(3)\)和平移\(t \in \mathbb{R}^3\)。
在先前的方法中,一部分方法使用可见部分匹配来估计两个视角之间同一物体的相对位姿,这些方法在视角之间的重叠较大时有效,但在视角变化较大时性能较差;另一部分方法通过重建3D模型来实现完全到部分的匹配。
提出的Any6D可以估计锚点图像\(I_A\)和查询图像\(I_Q\)之间的相对位姿\(\mathbf{T}_{A \to Q}\),方法包括两个部分:
- 首先使用image-to-3D模型,在不考虑真实世界的比例和位姿的前提下,从锚点图像重建归一化物体模型\(O_N\),然后通过确定实际对象大小\(s \in \mathbb{R}^3\)和位姿\(\mathbf{T}_{O_M \to A}\)来估计度量尺度物体模型\(O_M\),并将其在二维和三维空间中进行精确对齐;
- 接下来,我们利用重建的度量尺度物体模型\(O_M\)和查询图像\(I_Q\)进行姿态估计,通过融合\(\mathbf{T}_{O_M \to A}\)和\(\mathbf{T}_{O_M \to Q}\)推到出相对变换\(\mathbf{T}_{A \to Q}\)。Any6D框架的完整工作流程如图2所示。
3.1. Coarse Object Alignment
据我们所知,现阶段还没有可靠的RGBD单视角度量尺度重建方案可以有效的处理各种对象。所以这里使用“InstantMesh: Efficient 3D Mesh Generation from a Single Image with Sparse-view Large Reconstruction Models”。然而,一个关键的限制在于,3D物体重建只能生成具有归一化尺度的物体模型\(O_N\)(XYZ轴的范围都是\([-1, 1]\)),这意味着重建的模型未针对实际场景进行正确的尺寸缩放或空间定位。所以我们进行了物体对齐:首先估计物体形状\(O_M\)的粗略尺寸,然后通过联合求解\(\mathbf{T}_{O_M \to A}\)来优化该尺寸。我们的方法涉及在锚点图像\(I_A\)与归一化形状\(O_N\)之间进行3D和2D的物体模型对齐,具体包括变换\(\mathbf{T}_a \in \text{SE}(3)\)和尺寸\(s \in \mathbb{R}^3\)。
具体来说,我们基于\(I_A\),使用由粗到细的方法来估计物体尺寸\(s\)。首先通过比较\(I_A\)和\(O_N\)之间来自各自物体中心的点云来初始化粗略对象大小。虽然可以使用点的均值来直接估计中心,但是由于锚点图像中的部分视角问题和锚点图像中存在离群点,这种直接估计的方法是不可靠的。如图3(a)和图3(b)所示。
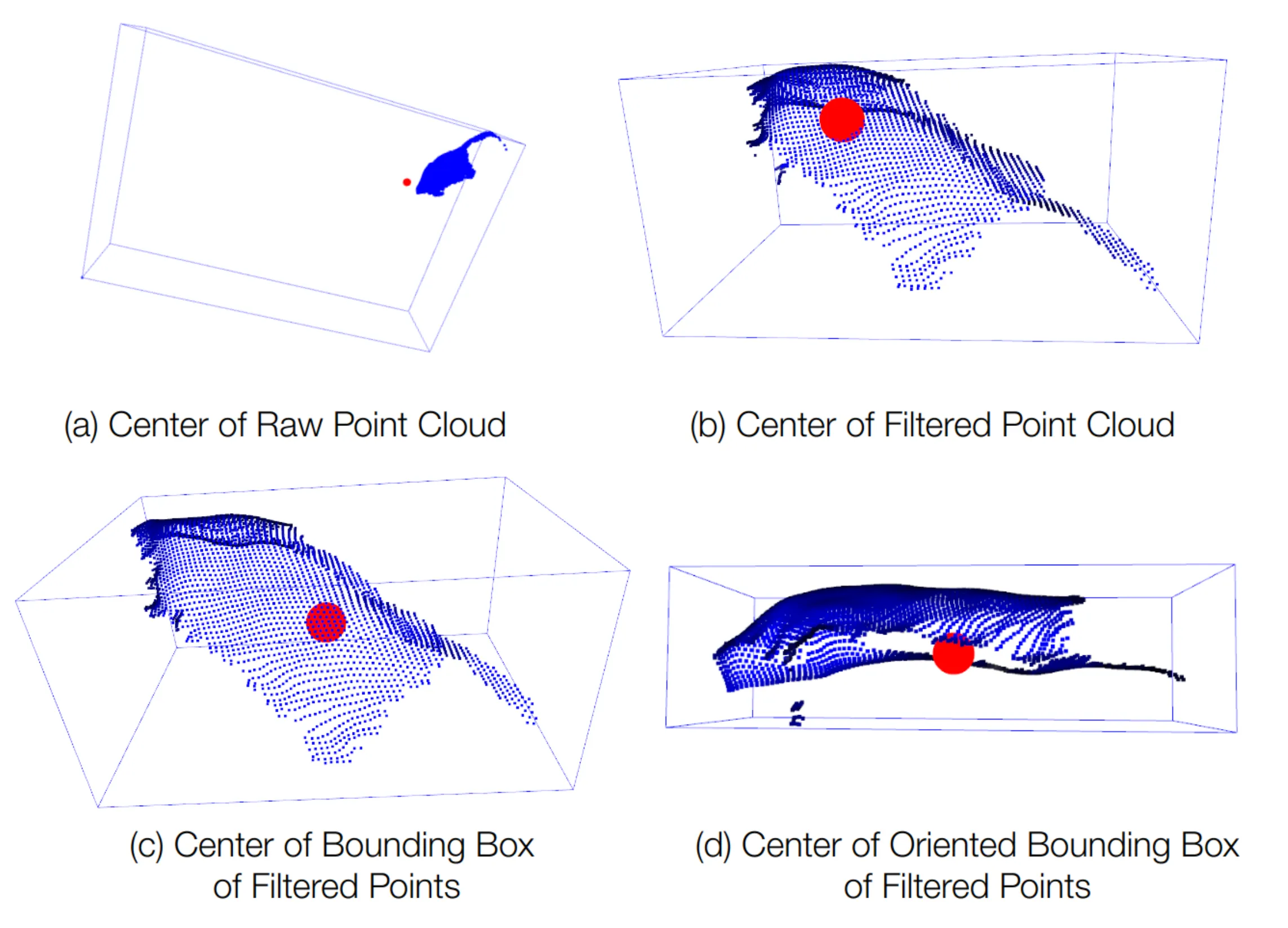
因为锚点图像中物体的部分可见性,使用简单的bounding box轴对齐方法同样也会导致不准确,如图3(c)所示。因此,我们提出使用有向边界框来确定物体中心,如图3(d)所示,这为\(I_A\)提供了更可靠的粗略中心估计。对于轴对齐,我们将有向边界框与XYZ轴对齐,对不同的旋转角度进行采样,然后计算\(I_A\)和\(O_N\)在不同角度旋转后bounding box之间的IoU。能够使IoU最大的旋转和缩放组合会把\(O_N\)变换为粗略对齐的物体模型,并将其更新为初始物体模型\(O_{M^\prime}\),随后\(O_{M^\prime}\)将被用于精确的位姿和尺寸估计。
3.2. Fine Object Alignment
方法首先重建粗略物体模型\(O_{M^\prime}\),然后通过物体和大小联合优化来优化位姿和物体大小。
优化部分的灵感来自“FoundationPose: Unified 6D Pose Estimation and Tracking of Novel Objects”,但是FoundationPose需要物体的CAD模型,在没有物体CAD模型的情况下,则需要多张有位姿标注的参考图像。因此,我们开发了一个联合模块,将大小估计任务融入到位姿优化过程中。这使我们能够可靠地同时估计大小和位姿。
优化流程主要包括三个主要模块:位姿估计、大小估计和轴对齐,这些模块在一个统一的过程中协同工作,通过在大小优化和位姿优化这两项任务之间交替进行来实现。我们首先使用\(O_{M^\prime}\)来估计初始位姿,同时优化物体大小。在FoundationPose中,采样生成位姿假设的过程只在\(\text{SO}(3)\)中进行,而没有考虑大小的变化。与FoundationPose不同的是,我们的方法除了在\(\text{SO}(3)\)中采样,还额外采样了不同的大小。具体来说,大小采样在每个轴上的范围为\(\Delta s \in [s_0, s_1]\)(其中\(s_0 = 0.6, s_1 = 1.4\))。然后我们使用FoundationPose中的模块来优化位姿假设,并将优化后的位姿进行渲染,以与查询图像比较。最优位姿的选择会基于FoundationPose中位姿选择模块给出的比较分数进行选择。当最优大小确定时,我们会将物体大小进行缩放,并进入到位姿优化阶段,包括一个轴对齐步骤,以实现更高的精度。这种更新后的对齐方式利用了大小和位姿的联合估计,比传统的基于IoU的方法具有更高的精度。
在优化了物体参数之后,我们确定最终的物体位姿\(T_{O_M \to A}\),它能为重建的物体模型提供精确的对齐。利用锚点图像\(I_A\),查询图像\(I_Q\)和重建的物体模型\(O_M\),我们通过组合两个变换来估计相对位姿\(\mathbf{T}_{A \to Q}\):从物体模型到锚点图像的变换\(\mathbf{T}_{O_M \to A}\)和从物体模型到查询图像的变换\(\mathbf{T}_{O_M \to Q}\)。相对位姿可以表示如下:
\[ \begin{equation}\label{eq1} \mathbf{T}_{A \to Q} = (\mathbf{T}_{O_M \to A})^{-1} \cdot \mathbf{T}_{O_M \to Q} \end{equation} \]
对于位姿选择,我们采用一个两阶段的渲染-比较策略。首先,一个位姿排序网络会通过比较渲染结果和裁剪后的观测图像来评估每个假设,得到一个嵌入向量以量化对齐质量。然后,我们对所有位姿假设的拼接嵌入向量应用自注意力机制,融入全局上下文信息,从而生成最终分数,以便选出最优位姿。
4. Experiments
4.1. Datasets
4.2. Metrics
4.3. Comparison with State-of-the-art
4.4. Qualitative Results


4.5. Ablation Studies
