【论文笔记】Attention Is All You Need
Attention Is All You Need
Abstract
1 Introduction
2 Background
3 Model Architecture
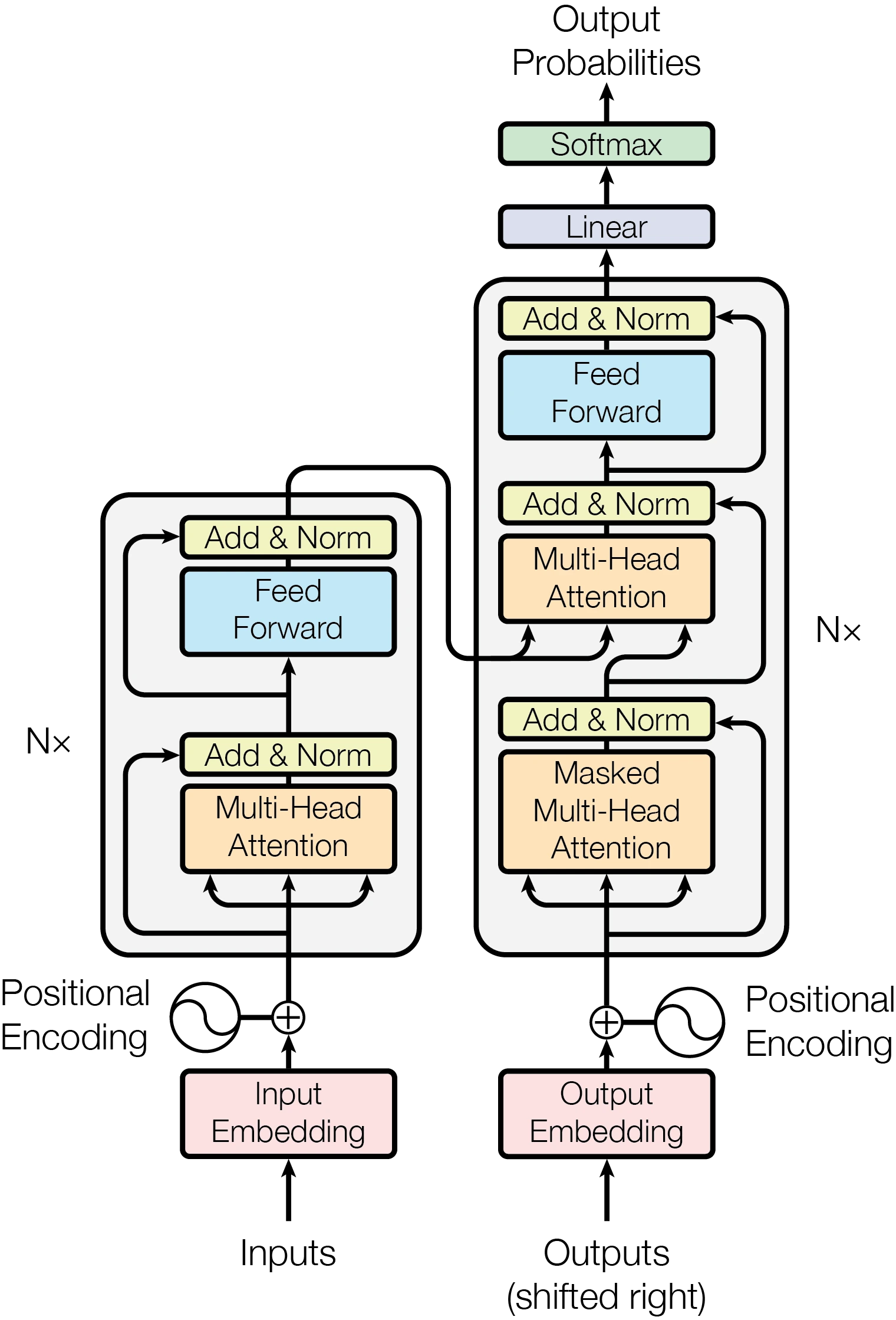
3.1 Encoder and Decoder Stacks
3.2 Attention
3.2.1 Scaled Dot-Product Attention
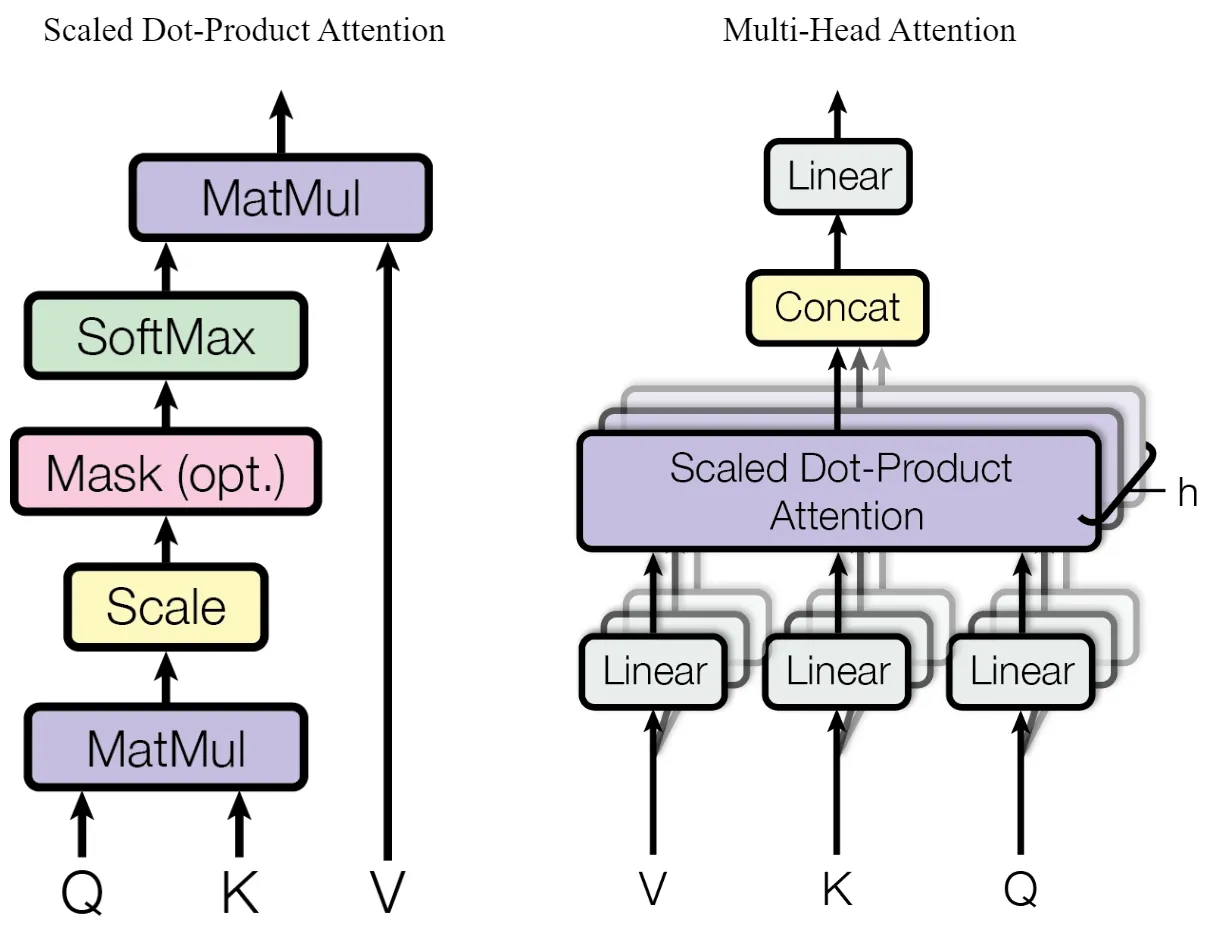
3.2.2 Multi-Head Attention
3.2.3 Applications of Attention in our Model
3.3 Position-wise Feed-Forward Networks
3.4 Embeddings and Softmax
3.5 Positional Encoding
4 Why Self-Attention
| Layer Type | Complexity per Layer | Sequential Operations | Maximum Path Length |
|---|---|---|---|
| Self-Attention | \(O(n^2 \cdot d)\) | \(O(1)\) | \(O(1)\) |
| Recurrent | \(O(n \cdot d^2)\) | \(O(n)\) | \(O(n)\) |
| Convolutional | \(O(k \cdot n \cdot d^2)\) | \(O(1)\) | \(O(log_k(n))\) |
| Self-Attention (restricted) | \(O(r \cdot n \cdot d)\) | \(O(1)\) | \(O(n/r)\) |
5 Training
5.1 Training Data and Batching
5.2 Hardware and Schedule
5.3 Optimizer
5.4 Regularization
6 Results
6.1 Machine Translation
| Model | BLEU | Training Cost (FLOPs) | ||
|---|---|---|---|---|
| EN-DE | EN-FR | EN-DE | EN-FR | |
| ByteNet [18] | 23.75 | |||
| Deep-Att + PosUnk [39] | 39.2 | 1.0 · 1020 | ||
| GNMT + RL [38] | 24.6 | 39.92 | 2.3 · 1019 | 1.4 · 1020 |
| ConvS2S [9] | 25.16 | 40.46 | 9.6 · 1018 | 1.5 · 1020 |
| MoE [32] | 26.03 | 40.56 | 2.0 · 1019 | 1.2 · 1020 |
| Deep-Att + PosUnk Ensemble [39] | 40.4 | 8.0 · 1020 | ||
| GNMT + RL Ensemble [38] | 26.30 | 41.16 | 1.8 · 1020 | 1.1 · 1021 |
| ConvS2S Ensemble [9] | 26.36 | 41.29 | 7.7 · 1019 | 1.2 · 1021 |
| Transformer (base model) | 27.3 | 38.1 | 3.3 · 1018 | |
| Transformer (big) | 28.4 | 41.8 | 2.3 · 1019 | |
6.2 Model Variations
| \(N\) | \(d_\text{model}\) | \(d_\text{ff}\) | \(h\) | \(d_k\) | \(d_v\) | \(P_{drop}\) | \(\epsilon_{ls}\) | train steps | PPL (dev) | BLEU (dev) | params ×106 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| base | 6 | 512 | 2048 | 8 | 64 | 64 | 0.1 | 0.1 | 100K | 4.92 | 25.8 | 65 |
| (A) | 1 | 512 | 512 | 5.29 | 24.9 | |||||||
| 4 | 128 | 128 | 5.00 | 25.5 | ||||||||
| 16 | 32 | 32 | 4.91 | 25.8 | ||||||||
| 32 | 16 | 16 | 5.01 | 25.4 | ||||||||
| (B) | 16 | 5.16 | 25.1 | 58 | ||||||||
| 32 | 5.01 | 25.4 | 60 | |||||||||
| (C) | 2 | 6.11 | 23.7 | 36 | ||||||||
| 4 | 5.19 | 25.3 | 50 | |||||||||
| 8 | 4.88 | 25.5 | 80 | |||||||||
| 256 | 32 | 32 | 5.75 | 24.5 | 28 | |||||||
| 1024 | 128 | 128 | 4.66 | 26.0 | 168 | |||||||
| 1024 | 5.12 | 25.4 | 53 | |||||||||
| 4096 | 4.75 | 26.2 | 90 | |||||||||
| (D) | 0.0 | 5.77 | 24.6 | |||||||||
| 0.2 | 4.95 | 25.5 | ||||||||||
| 0.0 | 4.67 | 25.3 | ||||||||||
| 0.2 | 5.47 | 25.7 | ||||||||||
| (E) | positional embedding instead of sinusoids | 4.92 | 25.7 | |||||||||
| big | 6 | 1024 | 4096 | 16 | 0.3 | 300K | 4.33 | 26.4 | 213 | |||
6.3 English Constituency Parsing
| Parser | Training | WSJ 23 F1 |
|---|---|---|
| Vinyals & Kaiser el al. (2014) [37] | WSJ only, discriminative | 88.3 |
| Petrov et al. (2006) [29] | WSJ only, discriminative | 90.4 |
| Zhu et al. (2013) [40] | WSJ only, discriminative | 90.4 |
| Dyer et al. (2016) [8] | WSJ only, discriminative | 91.7 |
| Transformer (4 layers) | WSJ only, discriminative | 91.3 |
| Zhu et al. (2013) [40] | semi-supervised | 91.3 |
| Huang & Harper (2009) [14] | semi-supervised | 91.3 |
| McClosky et al. (2006) [26] | semi-supervised | 92.1 |
| Vinyals & Kaiser el al. (2014) [37] | semi-supervised | 92.1 |
| Transformer (4 layers) | semi-supervised | 92.7 |
| Luong et al. (2015) [23] | multi-task | 93.0 |
| Dyer et al. (2016) [8] | generative | 93.3 |
7 Conclusion
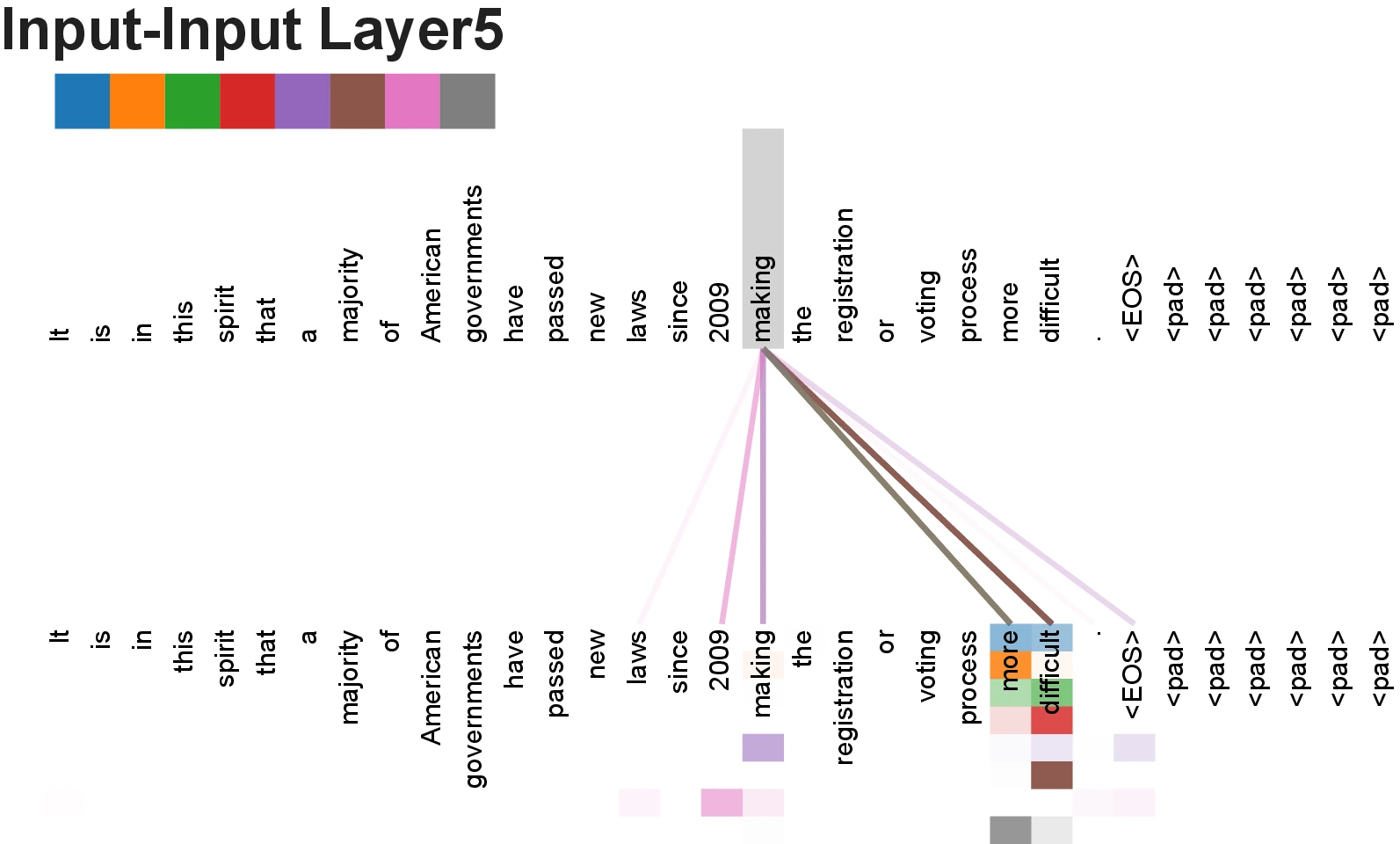
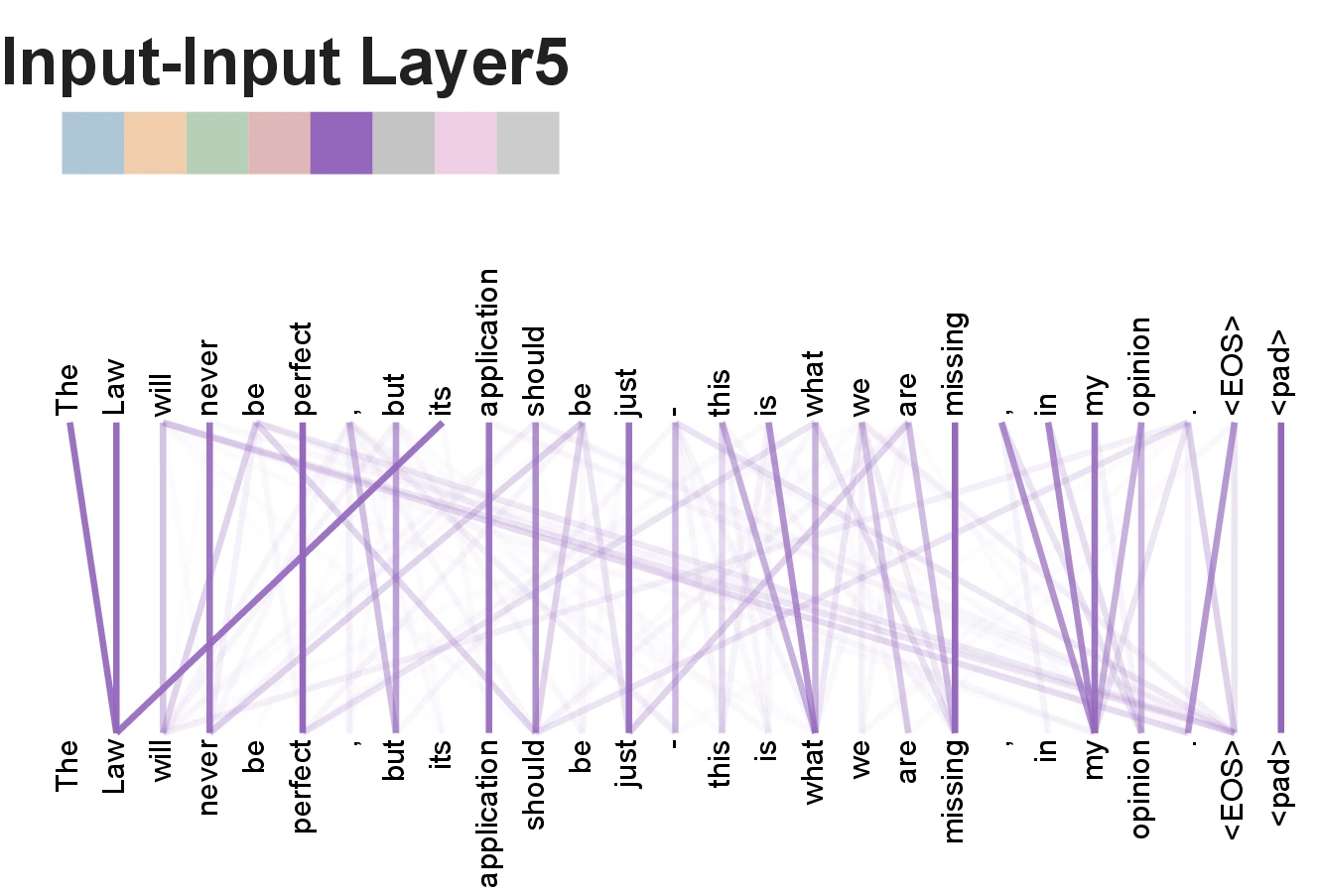
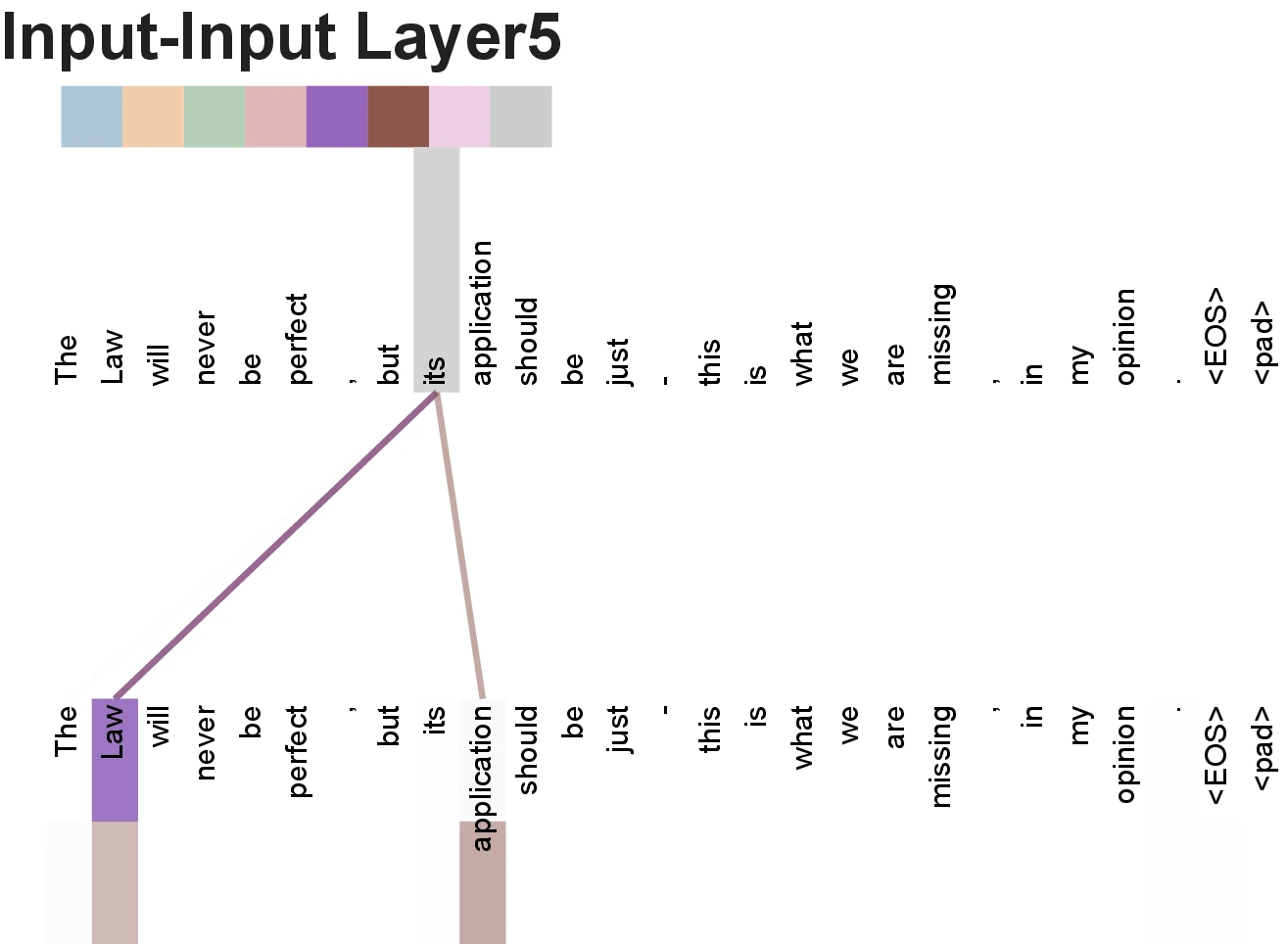
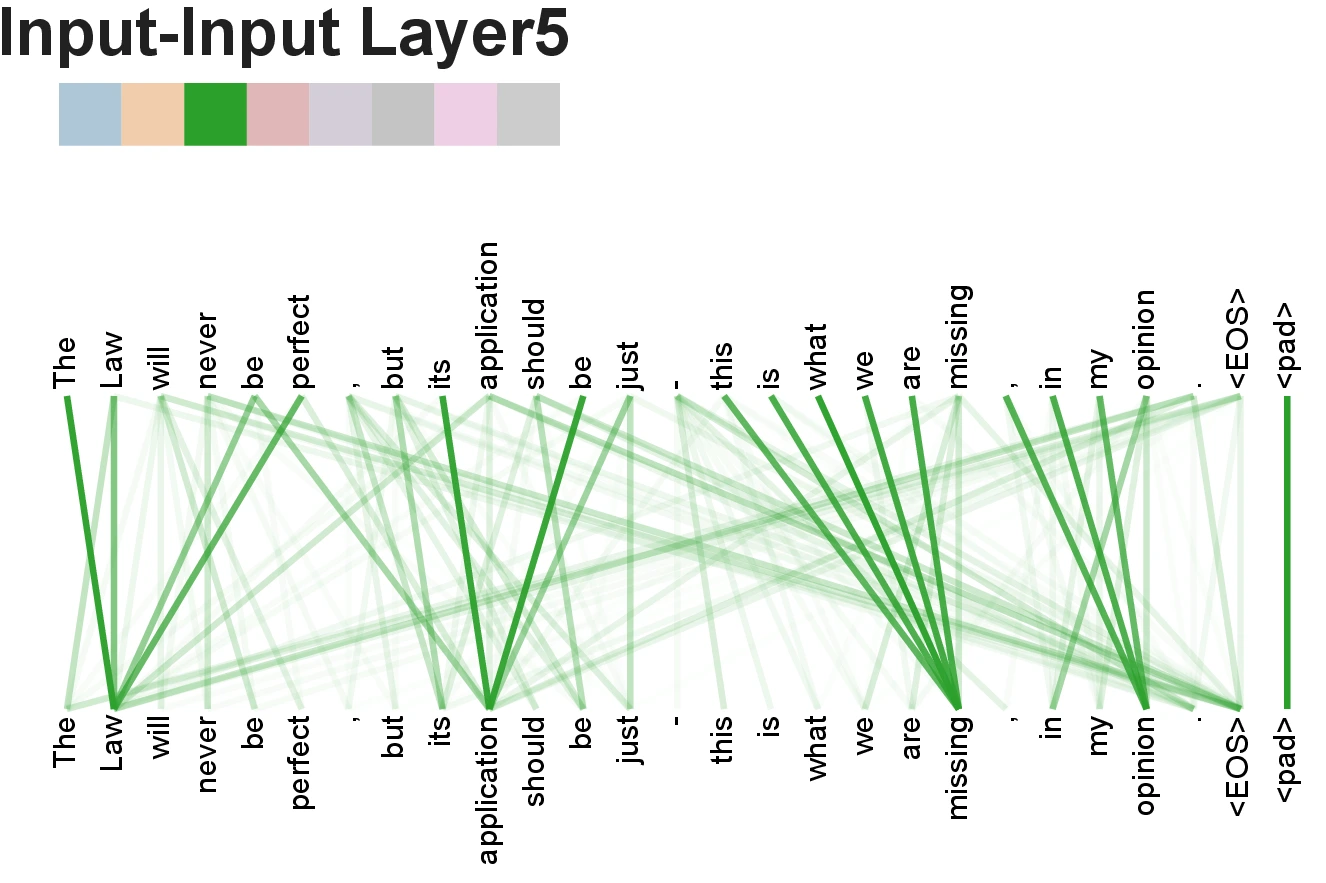
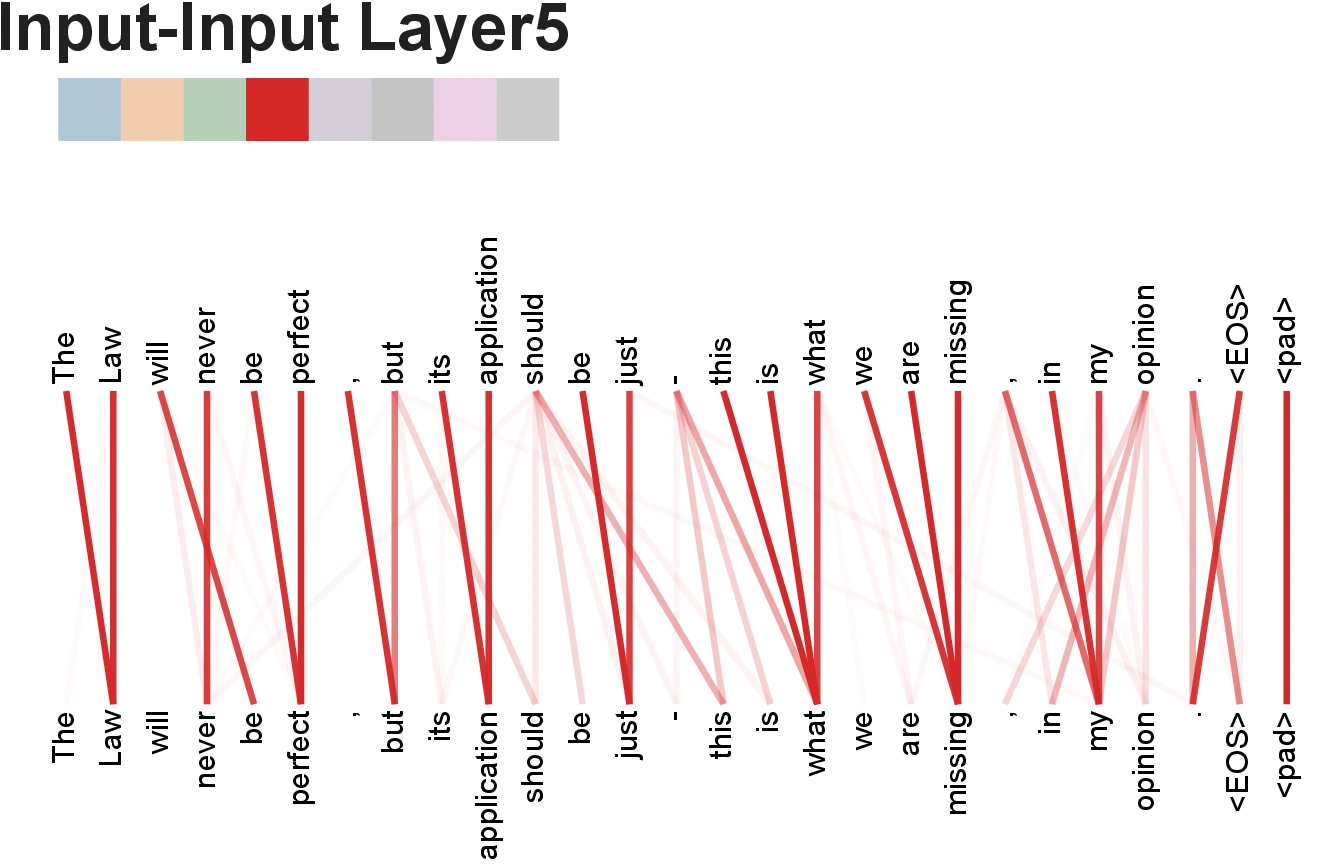
Attention Visualizations